天才ゲームプログラマ養成ギプス
やねうらおの考えでは、ゲームプログラミングに必要なテクニックとは、おおよそ800通りに分類されます。(800だけに嘘800です。すんません:p) そのうちの重要な12パターンを今年一年かけて解説しようと思っています。
内容はなーんも考えていません。12パターンの根拠もありません。毎月一回書いたら12ヶ月で12パターンかなーとか…すんまそん(笑)
プロ・アマ問いません。内容に対する、ご意見・ご感想などお待ちしております。雑誌への掲載も歓迎です。というか原稿書かせてくださいな(笑)
とりあえず、しばらくはゲームプログラミングに必須な実践テクニックをどこよりもおざなりに、誰よりもいい加減に解説しようかなって…(それじゃダメじゃん…)
第一章.キャラクター基底クラスの設計 2000/05/11
この講座、言語としてC++を選択します。コンシューマであってもC++を使う機会が増えてきているからです。(誰や、やねうらおは馬鹿だからC++しか知らないんだろうって言ってるのは…)
まずキャラゲーの基本ですから、キャラクターを表示することを考えます。仮に2Dのシューティングやキャラクターアクションゲームを制作することを考えてください。普通の設計では、それぞれのキャラクターは、それぞれ一つのクラスに対応していることでしょう。この基底クラスを設計してみましょう。
私が考える一番エレガントな方法とは、少なくともキャラクターは自立性が有ることです。例えば、
new CMissile;
とすればミサイルが生成され、あとはメインのプログラムからは、ミサイルについて意識しなくても済むような設計が理想です。
C++初心者の人は、
CMissile* lp = new CMissile;
として、このポインタをどこかで管理し、解放しなくてはならないと思うかも知れませんが、自立性の有るクラスに対しては、そのような管理は無用です。大規模になってきてプログラムが複雑になり、再利用困難になってくるのは、そのような相互依存性の高さゆえです。
そのような癒着を断ち切ってこそ初めてクリーンな政治、もといエレガントなプログラミングが出来るというものです。
そうは言うものの、そのミサイルを描画する関数CMissile::OnDrawは、いつ誰が呼び出すんだ?という疑問はあるでしょう。
当然、現存するすべてのCMissileのインスタンスに対するチェイン(=鎖。ここでは現存するすべてのCMissileインスタンスへのポインタの集合を指す。以後、「チェイン」と言う用語は、この意味で使います)は、どこかに無いといけません。
理想から言えば、それはCMissile設計者の手の届かないところにあるべきです。欲を言えば言語レベルで隠蔽されるべきです。まあ、これはC++の現状では難しいので、前者について考えてみましょう。
一つの方法は、CMissileをキャラ基底クラスCCharaBaseから派生させ、そのCCharaBaseのコンストラクタで、チェインに自己を登録し、CCharaBaseのデストラクタで、チェインから自己を削除することです。(デスクトラクタは派生クラス側のインスタンスをダウンキャストして使うのでvirtualにすることをお忘れなく)
実装例としては、STLで用いて
set<CCharaBase*> CCharaBase::m_lpCharaBaseList;
というようなstaticなチェインを用意して、CCharaBaseのコンストラクタで、
m_lpCharaBaseList.insert(this);
CCharaBaseのデストラクタで
m_lpCharaBaseList.erase(this);
すれば良いわけです。
(※ setではなく単純に配列ないし、STLのvectorで実装するほうが速い場合もある。ここでは議論しません)
あとは、すべてのチェインに対して描画フェイズで
for_each lp in m_lpCharaBaseList
lp->OnDraw();
とやります。(このfor_eachは概念的なものです)
STLのsetで実装しているならば以下のようになるでしょう。
set<CCharaBase*>::iterator it =
m_lpCharaBaseList.begin();
while (it!=m_lpCharaBaseList.end()) {
(*it)->OnDraw();
it++;
}
このあとで現れるfor_eachも、そのように“あなたの頭のなかで”展開されるマクロだとお考えください。
では、このチェインを嗅ぎまわり、数あるキャラクターの中からミサイルだけを削除するにはどうすれば良いでしょうか?一つの実装案としては、
for_each lp in m_lpCharaBaseList {
if (lp->IsMissile()) {
delete lp;
}
}
とやる方法です。言うまでもなくIsMissile()というのはCCharaBaseのメンバ関数で
virtual bool CCharaBase::IsMissile(void)
{ return false; }
virtual bool CMissile::IsMissile(void)
{ return true; }
というようになっているとします。もちろん、自分の型情報タグを返す仮想関数を用意しても構いません。それにはenumを利用してもいいし、単にintで番号を返してそれで判別してもいいです。もちRTTI(実行時型情報)でも構いません。
罠があるとすれば、setのeraseの実装によるものです。上のプログラムでdelete lp;した時点で、m_lpCharaBaseListからlpの値はeraseされます。なぜなら、lpが指すCCharaBaseのデストラクタが、m_lpCharaBaseList.erase()を実行するからです。
先のfor_eachのマクロを思い出してください!そのときそのlpの値を指しているiteratorはどうなるのでしょうか?これは消された値を指しているので不正な値を指すiteratorになります。
もちろん、eraseされた瞬間、その次の要素を指すようなスマートイテレータ(やねうらお造語)になっていれば、こんな苦労は無用なのですが…。
それならば、
set<CCharaBase*>::iterator it =
m_lpCharaBaseList.begin();
while (it!=m_lpCharaBaseList.end()) {
if ((*it)->IsMissile()) {
CCharaBase* lp = *it;
it=m_lpCharaBaseList.erase(it);
// これで次の要素を指すiteratorを得る
delete lp;
} else {
it++;
}
}
のようにやって、次の要素を指すiteratorを取得すればどうでしょうか?これは、ある程度うまく動きますが、それでも問題はあります。
まず無駄なことに、この実装ではm_lpCharaBaseList::eraseは二度呼び出されます。(delete lpしたときに、CMissileのデストラクタからも呼び出される)
そして、ミサイルひとつ消すぐらいで、こんな複雑なことをしなくてはならないのは、まっぴらごめんです。これでは、設計ミスと言わざるを得ません。(だからと言ってこれが使いものにならないというわけではない。これで十分であることもある)
そもそも、CMissileは、ミサイルなので、画面上の何かにぶつかったとき、自立的に消えるはずです。そのためにCMissileは自分自身のインスタンスをどうやって削除するのでしょうか?単純に考えれば、OnDraw関数内でdelete this;すれば良いだけのようですが、描画は先ほども言ったようにチェインを辿っていくため、OnDraw関数内でdelete thisした瞬間、そのデストラクタでそのチェインから外され(eraseされ)、OnDrawを呼び出すために、そこを指していたiteratorはその途端、不正な値を指すことになります。
デリートするためのプロパティとして、たとえば、
virtual bool CCharaBase::IsDelete(void) const;
このような関数を用意して、これがtrueならばそのインスタンスをdeleteをするような処理を一箇所で書けばどうかと言われるかも知れません。(場所は、描画フェーズの直後等)
それは、次のように実装できそうです。
set<CCharaBase*>::iterator it =
m_lpCharaBaseList.begin();
while (it!=m_lpCharaBaseList.end()) {
CharaBase* lp = *it;
it++;
if (lp->IsDelete()) {
delete lp;
}
}
deleteを呼び出す前にあらかじめインクリメントしておきます。setは整順化された順序列なので(要するに値か何かでソートされていることが約束されているってこと!)、これならば、次の値を指すことは約束されそうですが、これもうまくいかないことがあります。
それは、delete lpしたときに、CMissileがCCharaBaseから派生されたメンバ変数を持っている場合、CMissileのデストラクトタイミングで、そのメンバ変数のデストラクタが呼び出され、その結果、複数回のm_lpCharaBaseList.erase()が実行される可能性があるからです。
(※ もし、“そういう”コーディングスタイルを禁止するならば、このプログラムでも構わないのですが…)
結局のところ、スマートでないイテレータを使う限り、宿命的にこの問題に直面します。だから、自分でスマートなイテレータを実装する手のも一つの手です。
setがテンプレートで実装されているので、スマートイテレータも理想的にはテンプレートで実装すべきです。というか、set自体にそのようにスマートなバージョンも欲しい気もしますが…。
しかしauto_set(スマートポインタがC++のSTLではauto_ptrであるのに真似て)クラスを実装してみるのは夏休みの宿題としては面白いでしょうが、そもそも、setのようなものを効率的に実装しようと思うと2進木ないしn進木を実装する必要があるので、相当面倒です。そして、たかだかゲームのためにこんな抽象設計をやって四苦八苦するのは、考えものです。
もうおわかりかも知れませんが、問題は、iteratorでチェインを巡回している最中にそのチェインの要素をeraseすることに問題があります。よって、eraseするフェイズをずらしてやることが考えられます。
☆ 実装案その1
CCharaBase*と、データが適切なものであるかを判定するフラグ(m_bValid)をメンバ変数として持つ
class CCharaBaseListBase {
public:
CCharaBase* m_lpCharaBase;
bool m_bValid;
};
のようなクラスを設計し、こいつのsetを作ります。こいつに対する巡回は、m_bValidがtrueであるものに対してのみ行ないます。
☆ 実装案その2
別にm_bValidなんて使わなくても、ポインタがNULLであればinvalidだと判断したらいいんでないの?と思われるかも知れません。そうですね。それならば、
for_each lp in m_lpCharaBaseList
lp->OnDraw();
いう先ほどのマクロは
set<CCharaBase*>::iterator it =
m_lpCharaBaseList.begin();
while (it!=m_lpCharaBaseList.end()) {
if ((*it)!=NULL) it->OnDraw();
it++;
}
とすれば良いです。これならガーベジコレクタも簡単ですね。
set<CCharaBase*>::iterator it =
m_lpCharaBaseList.begin();
while (it!=m_lpCharaBaseList.end()) {
if ((*it)==NULL) {
it = m_lpCharaBaseList.erase(it);
} else {
it++;
}
}
となるでしょう。つまり、このようなガーベジコレクタと正当性チェック機構つきfor_eachさえあればそれで事足ります。setを継承してそのようなauto_setクラスを設計するのは面白そうです。
言うまでもなく、CCharaBaseのコンストラクタでは、m_lpCharaBaseListにinsertするものの、デストラクタではeraseせずに自分thisの値をfindで検索しNULLにします。
ところが、これがうまく動かないのです。
なぜなら、STLのsetは整順されていることを前提にしているので、値を
*it = 123;
のようにイテレータ間接で書き換えると、その部分が整順されていないことになり、n進木で実装されている場合(STLのsetは効率を追求するため普通そうなっているはず)、それ以降find関数が正常に機能しなくなります。(整順されていることを前提とするinsert,erase関数も使えなくなります)
よってsetで実装している場合、実装案その2は不可です。だからチェインをSTLのlistで実装する手もありそうですが、それだとeraseとfindがO(log N)のオーダーで済む(はずの)setに対してやや不利と思われます。ただそれは机上の話であって、実際はページングの問題やメモリキャッシュの問題、そしてそのゲームに出てくるキャラクター数などいろいろな要素が噛み合っているので事態は複雑です。ともかく、listならば実装案その2は可です。
もう一つ、別の問題があります。それは整順されていることの弊害が出ないかということです。
つまり、setで実装した場合、整順されてしまうので、あるCCharaBaseの派生クラスCMyCharaのOnDrawで新たにミサイルを生成するため、
CMissile* lp = new CMissile;
とやったとき、lpとthisとの大小関係、すなわちlp > this なのか lp < thisかは不定です。つまり、描画フェーズにおいて、CMyChara::OnDrawとCMissile::OnDrawのどちらが先に呼び出されるかは不定です。たいした問題ではないと思うかも知れませんが、同時にニ方向にミサイルを発射するために
CMissile* lp1 = new CMissile;
CMissile* lp2 = new CMissile;
を2回実行したときに、その大小関係がlp1 > this > lp2か、lp1 < this < lp2だった場合、片方だけ1フレーム早く描画されることになります。実際には、それほど問題になることは少ないですが、何フレームでこれをどこからどこへ移動させるという細かい要求通りに動かさなくてはならない場合、これは致命的である場合もあります。
結局そのような場合、setで実装するのをやめてlistで実装すれば描画順序をコントロールすることが出来ます。listで遅いのはfindとeraseと言いましたが、全検索になるから遅いのです。とは言っても、整順されていないデータ列に対してsetのようにO(log N)でfindするアルゴリズムは存在しません。しかし、CCharaBaseから、逆にそのlistの要素へのポインタ(イテレータ)を持っておけばfindする必要はありません。この場合、次のように書けるでしょう。
// 自分をdeleteしたいとき、自分がinvalidであることを示すために
// 逆方向ポインタ間接でlistの要素をNULLに変更するのは容易である。
*m_lpRevMyObject = NULL;
あとは、さきほどのようなガーベジコレクタにチェイン中のNULLである要素を削除してもらえばOKです。
ところが、STLのコンテナはあるサイズになったときに、自動的にサイズ拡張されるのでその瞬間、逆方向ポインタが不正になってしまう可能性があります。これは実装系に依存する問題かも知れませんが、少なくとも典型的なvectorの実装ではpush_backしたとき、サイズが一定を超えるごとに領域の再確保を行なうため、その瞬間、要素を指していたポインタ(イテレータ)は不正になります。listは要素をpush_backするごとに領域を確保(new)するような設計になっているならばその問題はないです。最悪、list::reserveで、あらかじめサイズを予約しておく方法もあり、それで実用上は十分という気もします。(神経質な人は構造体の中に逆方向ポインタへのポインタを忍ばせ、コピーコンストラクタで逆方向ポインタを正しいアドレスをポイントするように修正するのかも知れません。やねうらおはやる気しません)
今度は、現存するCCharaBaseから派生されたインスタンスすべてを削除することを考えてみましょう。直感的には、
for_each lp in m_lpCharaBaseList
delete lp;
ですが、このdeleteには、もう一つの問題があります。C++では、
CChara* lp = new CChara[3];
として確保したメモリを
delete lp[0];
delete lp[1];
delete lp[2];
というように分割しながら解放してはいけないからです。必ず
delete [] lp;
としなくてはいけません。何を当たり前のことを言っているんだ!と思われるかも知れませんが、そうなるようにfor_eachの部分を実装するのは困難です。さきほどのm_bValidのように、配列でnewされたかどうかを判定するm_bArrayがあればいいように思うかも知れませんが、いろいろ問題があります。
class CCharaBaseListBase {
public:
CCharaBase* m_lpCharaBase;
bool m_bValid;
bool m_bArray; // 配列で確保された先頭アドレスの場合のみtrue
};
一応、newは下位のメモリから上位のメモリに向かって確保されることは保証されており、STLのsetのイテレータで巡回するとき要素が昇順でソートされていることが保証される(はず)なので、配列の先頭をアドレスを要素として持っている部分だけm_bArrayをtrueにしておき、そこにぶち当たったとき
delete [] (*it).m_lpCharaBase;
とすれば、うまく行きそうですが、生成されたインスタンス側から自分は配列なのか?そして、その先頭なのか?を知る可搬性のある手段がありません。(後者は方法が無いわけではないですが…) よって、m_bArrayを誰がいつtrueにするかというと難しいのです。
おまけに、自分がヒープ上に確保されているのか、スタック上に確保されているのかを知る可搬性のある手段もありません。(Windowsに限定すれば可能ですが…) 要するに、この部分は手詰まりなのです。
| (補遺) いずれにせよ配列をポリモルフィズム的に扱うのは危険です。なぜなら、コンパイラが delete [] array; を見たとき、 for(int i=配列の要素数-1;i>=0;--i) { array[i].CBase::~CBase(); } のように変換するからです。(array実際は派生クラスのインスタンスを指しているのでarray[i]は 不適切。結局のところ、ポインタ演算とポリモルフィズムとは単に合わないのです/Scott Meyers著『More Effective C++』(pp.15-18)より) |
| (補遺2) > 自分がヒープ上に確保されているのか、スタック上に確保されているのかを知る > 可搬性のある手段もありません。(Windowsに限定すれば可能 この部分についてどうやればいいのか質問をいただきました。ここで説明するほどの余裕は無いので、MSJ 1995 Vol10 No.1,No.5を見てください。入手困難な場合、Best of MSJ Vol8.ワンポイントレッスンという本がアスキーから出ています。(pp.708-715) 余談ですが、その文中に出てくるScott Meyersとは『More Effective C++』の著者です。ついでに私の文中の「可搬性のある手段はない」は、この『More Effective C++』を参考にしています(pp.138-152) |
言うまでもなくヒープ上に無いときはdeleteしてはいけません。たとえば、あるクラスがメンバとしてCCharaBase派生クラスを持っている場合、CCharaBaseの派生クラスのインスタンスをすべて解放すると言っても、その部分はdeleteするわけにはいきません。ということで、この技法を使う限り、CCharaBase派生クラスをクラスメンバに持つわけにはいきません。CCharaBase派生クラスのポインタをメンバ変数として持ち、コンストラクタでnewして、デストラクタでdeleteするのは可です。しかし、その場合、
for_each lp in m_lpCharaBaseList
delete lp;
のようにして外部からdeleteされた場合、それに気づかず不正にアクセスしてしまう可能性はあります。困ったことですが、このようにしてアクセス違反を起こすプログラムはよく見かけます。
ここで、よく考えてください!自立性のあるクラスであるということは、自分の存在は不要と判断したら自動的に消滅するということなので、そんなクラス(のインスタンス)へのポインタを持っていること自体が不正であるという意見もあるかも知れません。だから、すべてはメッセージのブロードキャストによって行なうべきだとあなたは言うかも知れません。お説、ごもっともです。(メッセージのブロードキャストをあるクラスから派生されたクラスの全インスタンスに対する仮想関数の呼び出しとして実装するのか、それとも、もっと効率的なディスパッチルーチンを用意するのかはここでは問わないことにします) またある人は、そんなクラスへのポインタは効率の上からして不正ではない。消滅したことこそ何らかの方法で通知すべきだと言うかも知れません。どちらが良いかはここでは議論しません。
このへんの実装方法はケースバイケースです。それと、CCharaBase派生クラスの配列をnewするのはやめるのが無難かも知れません。そのことについて嘆くほどのことではないように思います。STLのスマートポインタ(auto_ptr)だってどうせ配列には非対応なんですから!
ここまで読んできて、ゲームを作るって難しいなぁ〜と思われている方がおられるとしたらそれは大きな勘違いです。実際のゲーム制作で、このようなクラス設計が必要になることはまずありません。キャラクター数がたかだか100しか出ないのであれば、100と固定で配列を確保しても何の問題も無いからです。だから、今回の話は戯言として聞き流すのも良いですし、そんなアイデアがあったのかと感激して、やねうらおにメシでもおごってくれてもいいです。(そんな奇特な人はいないか…)
まあ、これでようやくキャラクターの生成消滅の自立化が出来る土台が見えてきました。まだ先は長いかも知れません。というか、これが出来ないと何も始まらないという気がしますが、これがまったく出来なくてもゲームは作れてしまうような気もします。ゲームプログラミングなんて案外そんなものかも知れません。
余談ですが、私が思うに、このように現存するXXX型から派生されたクラスのインスタンスすべて(か、ある領域に属するもの)に対して、メッセージをブロードキャストする機構は、言語的にサポートされるべきです。こんなことも出来ずに、何がオブジェクト指向なんじゃい!と思わずにはいられないのですが、みなさんはいかがなものでしょうか。ご意見・ご感想などお待ちしております。(内容に対するものもね)
第一章のフォローアップ 2000/05/26
1.STLのlist
STLのlistクラスは遅いですね。さ〜さんが調査してくださいましたので、興味のあるかたは以下をご覧ください。
http://www1.webnik.ne.jp/%7Esanami/codemaster/index.html#CODE16
ついでなので、遅い原因も究明してレポートしてくださいな(笑)>さ〜さん
'00/06/12 修正記事あり。スーパープログラマーへの道 第AF回を参照してください。
2.deleteでオブジェクトを消していいのか?
最後の部分でちらっと触れた話題ですが、delete演算子でオブジェクトを削除したいと思っても、運悪くどこか知らないところからそのオブジェクトを参照していれば、削除できません。(削除できないように実装すべきです) つまり、その場で削除したい!というのは叶わぬ願望なのです。
これをC++ではどのように実装すれば良いでしょうか?一つの案としては、deleteでオブジェクトを削除するのではなく、削除はメンバ関数Killを介する方法です。Kill関数を呼び出されたら、それ以降、そのオブジェクトのメンバ関数をすべて無効化します。そして、ガーベジコレクションを行なうフェーズにおいてdeleteすると。
上の、「そのオブジェクトのメンバ関数をすべて無効化する」という部分の実装を、一番簡単に行なう方法は、Killが呼び出されたときにメンバ変数m_bValidをfalseにして、メンバ関数内の頭で、このm_bValidがfalseならば、何もせずにreturnするようにすることです。すべてのメンバ関数にこれをやるのは機械的な作業で、少々かったるい気がしますが、一番簡単でしょう。
第二章.サウンドマネージャの設計 2000/05/26
いい人材はコンシューマーに行って、エロゲー作ってるのはヘドロちゃんだけ(なんや、それってもの凄い差別用語ちゃうか?)とか言ってる人がいましたが、はいはい、それはきっと真実でございますですよ。
まー、ひとりのエロゲー製作者として言い訳させていただけるならば、それは開発費の少なさ、ひいては開発期間の短さにあります。裏を返せば、マーケットの小ささがネックなんです。
パソコンユーザーが急増していると言っても、それは猫もしゃくしもインターネットを使うようになってきただけで、ゲームのマーケットが急激に拡大したわけではないですから。
だからって、エロゲーばっか作っていると、やねうらおもヘドロちゃんだと思われてしまう!!(きっと思われてるに違いない) そんなのって嫌だ〜!!そんなことだから、19のガキんちょに馴れ馴れしくタメ口でメールされるんだよな〜。(そいつは情けないぞ、やねうらお〜)
先日、プレーステーション2の開発キットも購入したんで(笑)、あと3作ほどエロゲー作ったら、Windowsともおさらば出来るかも知れません。(させてよね〜(笑) でもドリキャスとXBOXやるからまた戻ってくるんだろうなぁ..) まあ、そんなこんなで、いままで自分が模索してきたテクニックを披露してみようかなとか思うようになったんですよ。これこそ、俺が求めていた内容だ!と言える人は、限られた人たちだけかも知れませんが、こんな内容でも参考になったという方、おられましたら是非、やねうらおにメールくださいな。(励みになります)
さて、あなたはサウンドを再生したいとき、どうやってますか?
CSound sound;
sound.Load("SE001.wav");
sound.Play();
のようにして、サウンド(効果音)を再生できるクラスは既に存在するものとします。サウンドクラスの設計から話していてはこの講座、いつまでたっても終わらないからです。(笑) WindowsでDirectSoundでサウンド再生を行なうクラスであれば、私のSDKを見れば少しぐらいは参考になると思うので、ここで説明はしません。
サウンドの再生なんて、サウンドの再生が必要となるクラスは、CSoundをクラスメンバに持っておき、コンストラクタでサウンドを読み込み、デストラクタで解放し、必要に応じて
m_sound.Play()
と呼び出せばそれで解決すると思うかも知れません。これは大きな誤りです。
たとえば、ホーミング弾にはSEが存在するとしましょう。前回、話したようにホーミング弾を担うクラスは自立性のあるクラスです。ホーミング弾が生成された瞬間にSEは鳴らないといけませんから、ホーミング弾のコンストラクタは、soundを読み込み、再生しようとします。すると、以下のような問題が浮上します。
1.生成された瞬間にサウンドをファイルから読み込んでいたのではリアルタイム性が損なわれる
また、三つのホーミング弾が同時にnewされた場合はどうでしょうか?
2.複数newされた場合、多重再生になってしまう。
これは、そう意図する場合もあるでしょうが、画面上に百発のホーミング弾が発生したときには百個のサウンドをミキシングして再生することになり、これは意図するところではないでしょう。
上記の1.2.の解決は簡単です。
某芸能人ではありませんが「仕事ならマネージャを通してください!」なのです。
そこで、SEManagerを作ります。以下のは、その昔、あるゲームで使うために僕の弟子が設計したクラスです。
class CSEManager {
public:
LRESULT Load(int nNo); // 読み込み
LRESULT Release(int nNo); // 解放
LRESULT ReleaseAll(void); // 全解放
LRESULT Play(int nNo); // 現在鳴っているならば妨げないタイプの再生
LRESULT PlayN(int nNo); // 現在鳴っていようが強制で鳴らす
LRESULT Stop(int nNo); // 止める
CSEManager(void);
~CSEManager();
protected:
bool m_bLoad[128];
CSound m_sound[128];
};
何をしようとしているのか、だいたいは想像がつきますね。
1.一度読み込んでいるもの(m_bLoad[nNo]がtrueのもの)は読み込まない。
2.現在鳴っているならば何もせずにリターンするタイプの再生→Play
3.現在鳴っている場合は、それを強制的に中断し、再生を開始する→PlayN
4.一度読み込んだものはRelease/RelaseAllで解放するまでメモリに残る。
5.Play/PlayNを呼び出したとき、もしm_bLoad[nNo]がfalseならば、Load(nNo);として、自動的に読み込む。
よって、Loadは、必ずしも明示的に行なう必要はない。(リアルタイム性が問われる部分では、事前にLoadしておく)
また、ゲームによっては、PlayNは必要ではなく、Playだけで十分かも知れません。
なかなか、面白そうなSEManagerですが、ところが、これでは設計ミスと言わねばなりません。
たとえば、ホーミング弾を60発、同時に発射したとき、ホーミング弾のクラスが60回newされて、PlayNが60回呼び出されると思うのですが、CSound::Playは何度呼び出されるでしょうか?おそらく60回呼び出されるのではないでしょうか?
これが、一般的にマズイと思われます。サウンドの再生のためには、音飛びが発生しないようにするため、ある程度余裕を持ってバッファに転送しなければなりません。バッファアンダーランに対して、1秒分の余裕を持たせるならば、22KHzステレオ16ビットの音質だと
22,528(22*1,024) × 2(ステレオ) × 16(bit) / 8 [bytes] = 90,112 [bytes]
もの転送が必要になります。サウンドの再生ルーチンの実装にもよりますが、おそらくは、Playを呼び出した瞬間、この転送作業が発生するものと思われます。これが60回。すなわち、
90,112 * 60 [bytes] = 5,406,720 [bytes]
5MB強のメモリ転送が発生することになります。秒間60フレーム、すなわち60FPSを実現しようと思うと、この転送が少なくとも1/60秒以内に終わらなければいけないことになりますが、それは平均的なCPUでは到底不可能でしょう。つまり、この部分で確実にコマ落ち(フレーム落ち)します。
もうお分かりでしょう。
つまり、同じフレーム内で複数回PlayNするときは、CSound::Playは1回しか呼び出さないように設計すべきです。
具体的な実装手段としては、CSEManagerに
bool m_bPlay[128];
のようなメンバを持たせ、フレームの描画タイミングでm_bPlayをリセットして、CSEManager::Playからは、CSound::Playを呼び出す代わりにm_bPlayをセットし、描画タイミング終了後、CSEManager::m_bPlayの要素のうちセットされているサウンドのみを再生する(CSound::Playを呼び出す)ということです。
あるいは、ゲームの性質によっては同一のフレーム内のCSound::Playを規制するだけではなく、2〜5フレーム以内のCSound::Playの呼び出しをも規制したほうが良いかも知れません。
そう言えば、15年ぐらい前に『Hacker』という雑誌(いまで言うならゲームラボのような雑誌)にゼビウスの遠藤氏が匿名対談のなかで、「同一フレーム中は、ビット立ててブロックしている」という趣旨のことを言われていたと思います。このようなサウンドマネージャは、古くから多用されている技法であり、ゲームを作る上で必須なのです。
今回は、簡単なので、もう少し突っ込んで考えてみましょう。このSEマネージャのインスタンスはどこに配置すべきでしょうか?
OOP信奉者は、アプリケーションには、唯一のアプリケーションクラスが存在して、それ以外のグローバル変数は存在しないべきだと主張します。これは、理念としては理解できます。そうなると、CSEManagerは、おそらくアプリケーションクラスCAppのメンバ変数として持つことになるのでしょう。
ところが、これにアクセスするにはどうすれば良いのでしょうか?CAppの唯一のインスタンス、theApp間接でアクセスするのでしょうか?仮にCAppのメンバ関数を
static CApp* GetApp(void) { return &theApp;
}
static CSEManager* GetSEManager(void) { return
&m_SEManager; }
とやって、
CApp::GetApp()->GetSEManager()->PlayN(10);
とやるんでしょうか?まあ、それでもいいような気もしますが(笑)、こんなことをするぐらいならば、CSEManager g_SEManager;とファイルスコープに置いたほうがよっぽどすっきりするような気もします。OOP信奉者は「ファイルスコープに変数を置くと、ある規模で破綻する」と信じていて、ファイルスコープに変数を置くことを避けようとしますが、「ある規模で破綻する」だけであって、10個や20個の変数をグローバルにしたぐらいでソフトウェアが破綻するとは到底思えません。逆に10個や20個の変数が管理できないのなら、プログラマとしての管理能力が欠如しているような気がします。
もう一つ。さきほどの配列の大きさ128という定数ですが、これにしても#defineで定数を設定するならば、それはグローバルにアクセスできるのではないか?と思います。近年C++で、constキーワードで宣言された定数、たとえば、
const int MAX_SOUND = 128;
は再定義出来る仕様に変わったはずですが、これをクラス内で宣言できひんのはなんでじゃーい!!とか思います。VC++6.0でこれやると、「純粋仮想関数の宣言に構文上の誤りがあります、'=0' でなければなりません。」とかエラー出るんですよ。おんどりゃ、誰が純粋仮想関数宣言しとんじゃボケー!! 「関数でない識別子が純粋関数であると指定されています。」何眠たいことゆうとんじゃ、このド阿呆!!とか怒りたくなりますね。(笑)
なんか、ここまで来ると、正規表現での置換やマクロをサポートした強力なC++のプリプロセッサを作ってやろうかとか思いますね。でも、作ったら作ったでそんなには使うこともないんだろな〜とか思うと、踏みとどまってしまうんです。そんなこったから、19のガキんちょに馴れ馴れしくタメ口でメールされるんだよな〜。(しつこいぞ、やねうらお…)
第三章.アルゴリズム概論1 2000/06/09
なんか、最近、退屈である。エキサイトできるものが無い。例のガキんちょにはなめられっぱなしだが(笑)、それというのも、このコーナーの内容が簡単すぎるのがその要因かも知れない。本当に天才プログラマーになりたい人がこのコーナーを見ているのか。(見てないだろう) そして、このコーナーを読んで本当に天才プログラマーになれるのか。(なれないだろう) だとしたら、やねうらおは既に天才プログラマーなのか。(んなわけないだろう) 自分で言ってて甚だ疑問である。(当たり前だわね) そんなわけで、このコーナーの内容が役に立ったときは、嘘でもいいからメールください。(なんや、嘘って(笑)) 「このコーナー読んだら、昨日の俺より256倍賢くなったような気がします」とかでも可。(誰もしないって、そんなメール…)
ところで、さ〜さんがオフ会のあと遊びに来たとき(遊びに来たんだよ〜。本当だよ〜。3日3晩トイレで食事も与えずに監禁なんてしてないです(笑))にも話していたのですが、大学教養レベルの知識があれば、あとはプログラマにたいしたノウハウなんてあるわけでもないと。そうですね。平面と直線の交差判定すると言っても、そんなことは高校の数学なのであって、プログラムの時間に勉強することではないのでしょう。本当にプログラマに必要なのは、ごくわずかの知識ではないかと…。
今回はそんななかから、とびっきりいらない知識…もとい、知っていると役に立つかも知れないプログラミングトピックを紹介します。
アルゴリズム概論ってことで、『データ構造とアルゴリズム』等の書籍を想像された方もおられると思いますが、もちろん、それは王道なので、ご自分で本を買って勉強してください(笑) 私は奥村晴彦氏の『C言語によるアルゴリズム事典』を中学のときに買って、それがバイブルでした。毎日、この本で紹介されている文献や論文を読んだりしてました。(難しくて分からないものも多々ありましたが、確実に得るものはありました)
あと、数学的な内容については技術評論社から出ている『NUMERICAL RECIPES in C』が非常に役に立ちますが、ゲームプログラマには少々難しいかも知れません。(ゲームを作るにはいらないかも知れません^^)
☆ あらゆるものごとをスケーリングせよ
そんなトレンドを逆行するかのように、今回は低レベルの描画ルーチンについて考えるのである。もちろん、この「低レベル」というのは、「基礎的なレベル」というぐらいの意味で、高級言語に対して劣っているだとか、おつむのレベルが低いとか、子供のころよく靴を隠されて困ったとかそういう意味ではない。
直線描画のアルゴリズムにブレゼンハム(Bresenham)というアルゴリズムがある。その昔、聞いたことはあったのだが、何のことかすっかり忘れていたという人が多いだろう。やねうらおも、久しぶりにブレゼンハムって聞いたもんで、どんなハムやねん?とか思った。(どうでもいいけど、ブレ全ハムって変換するの勘弁して(笑)>IME2000) そんなわけで、Fussyさんのページを紹介させていただくことにする。
http://www.people.or.jp/~fussy/index.htm
そうなんよね〜。要するに、何かの拍子に割り算をする。割り算をするのは直線の傾きを求めるためだったり、内分点を求めるためだったりするわけだが、この割り算をすると端数が出る。この端数を無くすためだけに浮動小数を使うというのは、具の骨頂だとブレゼンハム氏はおっしゃるわけだ(笑)
x/yで端数が出るなら、この分母のy倍しなさい。このように、y倍というメガネを掛けて(スケーリングして)物事を考えなさいと。そうすれば、整数だけで解決するし、誤差は一切出ないのではないかと。たったそれだけのことだが、初めてこれを知ったときは、なんだか神秘的なものを感じたものだ。(しかし、その神秘性に対して数学的な理解が得られたのは、集合論を学んだ後になってからだったが…)
ところで、Pentiumでは浮動小数点レジスタが有り、浮動小数点の計算は1命令で終了するので、浮動小数点のほうが速いのでは?という議論もよく議題にのぼるのだが、どうもペアリング等の問題があるので、ライン描画はやはり整数命令で行なったほうが速いらしい。
それとブレゼンハムでライン描画する場合、両方の端点から開始できる。(ダブルステップブレゼンハムと呼ばれる。ハムの量も2倍ってわけだ←違うだろ…) 詳しくは、前述のFussyさんのページにある。(その他、ブレゼンハムによる画像の拡大縮小についての解説もあるので、その手の話題に興味のある方は、一度読んでみる価値はあるでしょう) ('00/08/20 いや、ダブルステップブレゼンハムは、これとは違うようだ。やねうらおは、勘違いして覚えていました。詳しくはFussyさんのページを見てね)
実際にラインルーチンを自前で組むことはあまり無いかも知れないが、アンチエイリアス付きラインルーチンを作ることはあるかも知れない。そんな読者諸氏のために、原理を説明。
http://www.din.or.jp/~keijiro/junks/aaline/
このアルゴリズムをブレゼンハムで行なえば良い。輝度値もあらかじめスケーリングしておくと良い。ここには、MMX用のコードで書かれた優秀なサンプルソースも紹介されている。(ちなみに、このアルゴリズム自体は、AALINEとして画像処理の世界では有名) この発展形として、アンチエイリアスポリゴン等も考えられる。(10年ぐらい前にそういう研究が盛んでした)
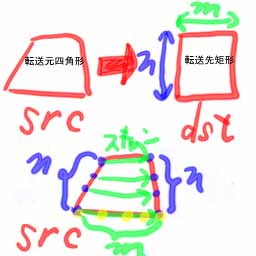
その他、ブレゼンハムは回転拡大縮小等の高速化にも応用できる。画像まわりではとりわけ利用価値が高いのである。たとえば、四角形を矩形に転送する場合を考えてみよう。モーフィングなどの基礎となるルーチンだが、
(画像汚くてすんません。ご飯食べながら描きました。<行儀悪いなぁ…)
転送元四角形をスキャンすることに始まる。まず、斜辺のn−1等分した点とその対辺をn−1に等分した点をつなぐライン(緑色のライン)に沿ってスキャンしていく。緑色のラインを、さらにm回スキャンされるようにm−1等分した点(黄色の点)が、転送すべきピクセルなわけである。こういう処理を行なうとき、ブレゼンハムでやれば誤差が出ない。('00/08/20 但し問題あり。第五章を参照すること) ちなみに、上の四角形→矩形のアルゴリズムは、僕が考えたものだがルーチンが複雑になるため3角形で行なうほうが良い場合もある。(多少ひずむが…) この「僕が考えた」は嘘ではないが、誰でも思いつきそうなアルゴリズムなので僕が世界で最初ではない。(だろう)
一般に、板ポリ(板状のポリゴンにテクスチャを貼っただけのもの。要するに、実際は3次元計算をしているのではなく、このような図形変形によって、擬似的に3次的に見せようとする表現手法のこと。例/ぱらっぱラッパー)は、転送元は矩形で、転送先が四角形であるほうが多いですが、その場合も、ブレゼンハムが使る。というか、来月号のCマガ(2000/7月号)で、そういうのって紹介されてるんではないでしょうか。うーん。タイミング悪いなぁ(笑)
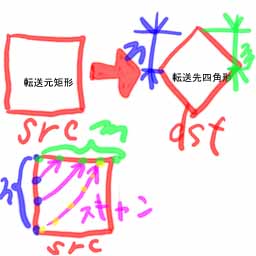
(画像汚くてすんません。左手でタコヤキ取って頬張りながら
右手でタブレットで書きました。<行儀悪いなぁ…)
一応、図示。実装は、さきほどのより、少し面倒です。子供のころ、自力で思いついたのですが、その後シェーディングしているプログラムのなかで見てがっかしした覚えがあります(笑) やっぱ誰でも思いつくんですね。(というか、これ以外の方法があるなら言ってみろとか言われそう(笑))
これの応用例として、転送元も転送先も(任意の)四角形の転送というのもあります。上のが出来たら、それはそんなに難しくはありません。考えてみてください。
☆ 乱数発生ルーチン
ゲームで擬似乱数が欲しいことがある。C言語のrand関数では、乱数の種を設定しても、それは実装系依存になってしまうし、お世辞にもそれほど速くない。周期もそれほど長くない。(ことがある) そんなわけで究極の疑似乱数生成アルゴリズムMersenneTwister法について載せているSYNさんのページを紹介します。
リンク許可をお願いしたときのリターンメールからちょっと引用。
| やねうらお様から直々にメールを戴けるとは感激です。(^^) やねうらお様のWebページから学んだ事も数多く、感謝しております。 私のページって、乱数生成のMT法のページ以外からはどこからもリ ンクされてないので、普通の人が見つけるのは困難です。海外から は来てますが・・・。一体どこからたどり着いたのでしょうか(^^; |
私のページも何かのお役に立っているのかと思うと大変、恐縮です。(さすがにこのようなメールをいただくと、馬鹿なことばっか書いてないで、たまには役に立つこと書かなきゃ!とか痛感しますね〜) ちなみに、SYNさんのホームページには、「乱数発生」で検索していたときに辿りつきました。海外のMT法のページから辿りついたんなら、かっこよかったんでしょうけどね〜(笑) いけてねえ〜>俺
☆ アセンブラを特訓せよ!いや、今回の趣旨から外れるのですが(笑)、少し息抜きということで。
今後、DreamCastやXBOXのマーケットを考えると、Windows開発する機会は無くなるどころか増えてくるのかも知れない。ならば、アセンブラぐらい勉強しておいても損はないだろう。アセンブラに関しては、IntelのPDFファイルを入手してやっている人がほとんどだろう。
しかし、これにはいろいろ嘘が含まれるので、以下のものも参考にしたほうが良いだろう。
http://www.csl.sony.co.jp/person/fnami/pentopt.htm
ここに掲載されている表は、やや古いバージョンなので、詳しいことは原文
をここから入手することが出来る。日本語訳されてから、新たに追加された章については、一読しておく価値がある。
見ていて気づいたのだが、CerelonはほとんどPentiumII扱いになるようである。
試しにこのテキストの一部をデジキューブ販売の「こりゃ英和」(\2,980)で変換してみると…。こうなった。↓
「もし規約が期待されるより際立ってより遅いなら、最もありそうな目的はそうです:お嬢さん(チャプター7)、不整列にされたオペランド(チャプター6)、初回の罰金(チャプター8)、ブランチ mispredictions (チャプター22)、インストラクションフェッチ問題(チャプター15)、が登録するキャッシュが売店(16)、あるいは長い依存心鎖(チャプター20)を読みました。」
なんや?「最もありそうな目的はそうです、お嬢さん」やて?なんや、これ三流エロ漫画か!?調べてみると、「お嬢さん」は、cache misses(キャッシュのミス)の訳語のようだ。それになんや?「初回の罰金」って。ああ、罰金はペナルティの訳語か。しかし、誰が罰金払うっちゅーんじゃ! そして、「キャッシュが売店」ってなんや?キヨスクでは現金清算ってことか? んんん。どうも「売店」はストール(stalls)の訳語のようだ。「読みました」は、register read stallsのreadが動詞として解釈されたようだ。こんなことなら自分で訳したほうがよっぽど早いぞ。この訳では、お笑い以外の何ものでもない。関数呼び出しのcallは、「電話をかける」とか変換する始末。そこにvoidとか入っていると「無効な」とか訳されて、「無効な電話をかける」とか。誰が無効な電話するっちゅーんじゃ!面白すぎるぞ、こりゃ英和。すなわち、これはギャグソフトなんやな?(笑)
ともかく、2,980円のソフトに技術文章は辛かったようだ。(新聞のニュースなどはある程度の精度で訳せるのだがなぁ…>こりゃ英和)
第四章.モーションブラー 2000/06/29
今回は、モーションブラーの説明をする。どうも、世間ではモーションブラーに対する認識が甘すぎる!モーションブラーなくして、次世代のゲームは有り得ないとここに断言しておこう。そして、ブラー(ぼかし)にかかる計算量を誤解している人が多い(メガデモで有名な某氏すら誤解している)ので、後述する。
まず、モーションブラー(Motion Blur)の原義は、やねうらおの知るところではないが、確かフィルム用語だったような気がする。カメラのシャッターの露光時間内に、物体が移動しているがために、軌跡が残ってしまうのだ。つまり、この原理からすると、ブラーは、一定時間内の物体の軌跡による像であって、いわゆる残像とは異なり、トーンを落として重ねて行くべきものではない。これを狭義のモーションブラーと呼ぶことにする。
しかし、人間の目には、残像というのが残る。これは、映像刺激がインパルスとして神経細胞を励起した結果、その冷却期間に見せる嘘の映像なわけである。これがあって、初めて動いている映像として人間は認識する。そこで、動きの遅い映像(静止画像もここに含まれる)に対して、意図的にこのような残像を入れてやることにより、動きを擬似的に表現することが出来る。これを、広義のモーションブラーと呼ぶことにしよう。
逆に、フレームレートの高い画像に対してモーションブラーを入れると、それはくどすぎる(例/バーチャファイター3)という結果になりかねない。そのへん気をつけて使わなくてはならない。
狭義であれ広義であれ、モーションブラーというのは、時間軸に対するアンチエイリアスであると考えられる。
ここまでは、まあ通論であって、やねうらおがとやかく騒ぎたてるほどのことではない。ここでは、広義のモーションブラーという概念を拡張することを考えてみよう。
たとえば、物体が肉眼で追跡できないほど高速で動いた場合はどうだろうか?手品でミスリーディングによって、ある方向からある方向へ移動するものだと思い込まされているような場合、そちらに移動したように見えることがある(実際は、そちらには移動していない) つまり人間は、文脈的ないし状況的な補間によって、時間軸に対するアンチエイリアスをかける過程において、ありもしない像を作り出すのだ。
もっと別の言い方をしよう。Aという地点から、Bという地点に物体が高速に移動したときに、マバタキをしてしまったとしよう。その後、その物体はどう映るだろうか?きっと、その物体が存在していたと思われる軌跡を頭のなかで自動的に補間するのではなかろうか?つまり、通常、人が映像を理解する神経回路を逆に辿り、残像パルスを勝手に生成してしまうのである。これは、人間のニューラルネットワークが入力層からは階層を形成しているにも拘らず実は内部で、連想記憶的に物事を想起し理解するシステムになっていることに由来するものと思われる。(深くは議論しない) つまり、(あまり知られていないが)人間は想像のなかで本当の痛みを感じることが出来るのだ。
読者の理解を超えて脱落者が増えてこないうちに結論を書こう。(というか、やねうらおが変人扱いされないうちにか^^)
人間が高速に動く物体に対して見える像というのは、像の残像だけではなく、肉眼で追いきれなくなり無意識下で時間軸に対してアンチエイリアシングするために作り出された虚像が含まれる。その虚像とは、物体の移動経路それぞれの存在確率に基づくものである。(量子力学的なものをイメージするとわかりやすい) ただし、存在確率は、そのときの人間の心情によって変化する。こちらから、こちらに動いたはずだ、動くはずだ、と思っている人にとっては、その部分の存在確率は異常に高いだろう。
そういう意味では、広義のモーションブラーにおいて、嘘の方向からの残像を自由に入れるのはNGではない。直線的に移動するからと言って、直線方向の残像だけを残す必要はない。つまり、高速に右に移動した場合、ブラー処理においてあるピクセルを、そのピクセルより右にあるn×1矩形の加重平均にする必要はない。n×m矩形の加重平均にしても良いだろうし、3角形や扇形にしても良いだろう。
今回は、一番基本的な、n×nの範囲を単純に加重平均する処理について考える。単純に考えれば、あるピクセルの値を求めるのに、n×nの領域を調べないといけないから、計算量はO(n^2)だと思う人が多い。これが大嘘なのである。
これは、ぼかし処理についても言えることだが、n×mのぼかしは、リニアにスキャンしていくならば、あるピクセルの隣のピクセルの値を求めるのに、ピクセル全体について再計算する必要はない。つまり、
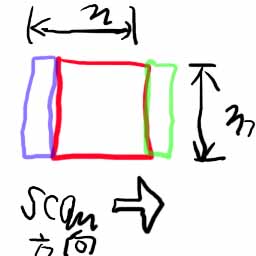
あるピクセルの値を計算するために、赤+青紫のエリアのピクセルの合計を求めた、その後、その右隣のピクセルの値を計算するならば、前回の合計から青紫の部分を引いて、緑色の部分を足せば良い。これにより、1×mの領域の再計算だけで済む。では、その1×mの領域の足し算を、必ずしないといけないのかというと、そうではない。
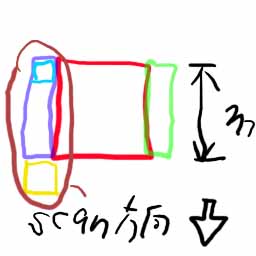
この紫の部分に着目すれば、この一つ下のピクセルについて、青紫の領域がどうなるかを考えると、黄色の部分のピクセルが1つ増えて、青の部分のピクセルが1つ減るということだ。つまりは、各ピクセルに対する青紫の部分の計算を、このようにして先に済ませておけば良いのである。よって、ブラー形状が矩形の場合、ブラー面積m×nの大きさがいかに大きくなろうと、計算量は実は一定なのである。(誰でも思いつきそうな気もするが、他のどこでも見たことが無いので、やねうらおがオリジナルということを主張してみる^^)
天才プログラマを目指す諸氏は、ブラー領域がm×nのピクセルではなく、三角形領域の場合等についても考えてみること。また、MMX等での実装を試みること。そして、ブラー領域が時間に伴って変化するときに前回の計算結果を生かせないか考えてみること。案ずるな!モーションブラーは重くない!(といいな〜^^)
第四章のフォローアップ 2000/09/17
池内さんのホームヘージにこのアルゴリズムが紹介されているという指摘を受けました。なるほど、あちらのほうが、日付が早いので私のオリジナルではないようです。あと、信号処理の分野で平滑化フィルタのアルゴリズムとしては有名なものだという指摘も受けました。そうだったのか〜。
何にしても、こんな程度のアルゴリズムは誰でも思いつくっちゅーことでんな^^;
第五章.モーフィング 2000/09/20
3Dはモーションブラー、2Dならばモーフィングでしょうってことで、今回は、モーフィングの説明を行なう。
いつも絵空事を話していると思われると癪なので、今回は実装例を用意した。yaneSDK2ndのサンプル2がそれなので、yaneSDK2ndのほうのCMorpherを見ていただきたい。まあ、こんなものは、私の手に掛かれば、あちょーってやって、むちょーってやって、きゅーきゅーってやれば完成だ。(それではちっともわからんがな!)
しかし、お世辞にも、あまりいい実装ではない。結局、転送元:任意四角形→転送先:矩形という、自由変形ルーチンがボトルネックになるわけで、その高速化の可能性については、スーパープログラマーへの道の第C4回、C5回で述べているので、そちらについても参照されたい。
まずは、任意多角形→任意多角形への自由変形ルーチンについて簡単に述べる。
第三章で書いたような任意四角形→矩形転送の場合、四角形の左右の辺をn等分して、それぞれの内分点を結ぶラインを、今度はm等分してスキャンするというような処理になる。このとき、ブレゼンハムが有効かというと、そうではない。理由は、ブレゼンハムは整数倍という眼鏡(俗に言うスケールファクター)を掛けて物事を見るという考えかたなのだが、n等分とm等分しているので、n×mのスケールファクターを掛けて考えるか、それともnのスケールファクターを掛けて、それをラインをスキャンするときにmのスケールファクターに変換するかする必要がある。これが面倒なのである。
実際のところ、整数部12ビット+小数部20ビットのLONGで持ち、それでスキャンして行くほうが高速だし、これで現実的な誤差が出るとも思えない。また、誤差が出たとしても、小数部は最後は切り捨てされていると考えられるので、最後のところで領域から越える(オーバーシュートする)ことが無いことは保証される。そんなわけで、モーフィングのスキャンにおいてブレゼンハムは無用なのだ。
どうでもいいが、32bit×32bitの掛け算は64bitになる。このあと32bitの整数で割れば、結果は32bitになる。一時的に64ビットになるので、DWORDDWORDとか、LONGLONGだとかINT64だとか、そういうのにキャストする必要があると思っていたのだが、このためのMulDivという関数が用意されていることを最近知った。こういう処理を書くときはなかなか便利である。(MulDiv以外にも、似たような関数がいくつかあるので、興味のある人はオンラインマニュアルでMulDivを調べてみること)
整数部12ビット+小数部20ビットで(x,y)の座標を持てば、MMXならばpacked dwordのaddで1回のベクトル加算が終了する。これを実アドレスに変換する作業だが、サーフェースの横幅が512とか2のn乗ならばシフトで済むのだが、一般的に言ってそうも行かない。しかし、乗算は3クロックでしかもペアリング不可(だったかな) Pentiumに至っては、乗算は9クロックで同じくペアリング不可。このアドレス算出部分以外は4クロック程度で済むのに、アドレス算出にこんなに時間がかかったのではやってられない。そこで、サーフェースの各ラインの先頭ピクセルのアドレスは事前に計算してテーブルに持っておくことにする。またスキャンは通例局所的な参照になるだろうから間違いなくこのテーブルはL1キャッシュに入る。
それでは、転送元・任意n角形→転送先・任意n角形という転送について考えてみよう。3Dのシェーディング処理などでは有名だろうから、ここで敢えて説明するまでもないだろうが、私なりの方法を簡単に述べる。わからない人はこの説明でわかろうとせず、画像処理等の参考書籍を読まれたほうがいいだろう。少なくとも、多角形の高速塗りつぶしアルゴリズム(フロントスキャンコンバージョン)について知っていなければ何のことだかわからないだろう。知らない人は、第三章で紹介したfussyさんのページ
http://www.people.or.jp/~fussy/index.htm
を見ていただきたい。
まず、問題を簡単にするため、3角形の場合について考える。転送先を水平に描画して行く。そのためには、転送先の3角形の頂点をy座標でソートして、一番上の頂点から描画して行く。このとき、この3角形(POINT [3])が、右周りか左周りかを決定しなくてはならない。(なぜなら、この一番上の頂点に対して、どちらが左側の辺で、どちらが右側の辺であるかをスキャンの前に知っておかなければならないから) これは、ベクトルの外積を使えば一番簡単だろう。一番上の頂点をa,残りの頂点をb,cとすれば、Vab×Vacの符号でわかる。
そのあとは、転送先3角形の左の辺と右の辺を結ぶ水平ラインに相当する部分をソースから転送していけば良い。第3章の任意四角形→矩形の応用である。転送先のスキャンが、次の頂点に達した場合、新たにスキャンベクトルを設定しなおす。最後の頂点になるまで、これをこれを繰り返す。
同様にn角形になった場合も、転送先n角形の頂点をy座標でソートして、外積によって頂点が右回りか左周りかを決定し、同じことをすれば良い。ただ、ねじれていたりしてはダメで、また凸形でなければならないという制限はある。後者の制限を回避するには、3角形に分割して処理するのがてっとり速い。よって、一般的な変形を行なう場合は、転送先は矩形ぐらいのほうが都合が良いし、そうでなければ3角形に分割してやらなければならない。
簡単ではあるが、任意多角形→任意多角形への自由変形ルーチンの説明はこれで終わり^^;
さて、モーフィングの具体的な処理だが、私のCMorpherの使いかたは、転送元と転送先の対応する点の集合Spを与えれば、あとはフェーズ(0-256)だけ指定すれば、求める画像が描画される。実にお手軽である。
原理を簡単に説明する。モーフィングは、元画像1から元画像2になめらかに変形するものとする。元画像2上に、テキトーに格子点をとり、その格子点Pが、元画像1において、どこの点であったか(点P’)を求める。あとは、その点P’からPに向かってフェーズに応じて内分した点を、転送元四角形の一点とすれば良い。(残りの3点も同様にして求める)
点P’を求める方法だが、これは、格子点Pに対して、その近傍3点を、集合Spから探す。そうすると、その近傍の3点Srが同一直線上にないなら3点Srに対応する元画像のSr’3点から、元画像における点Pに対応する点P’がどこであるかがわかる。一応、図示。
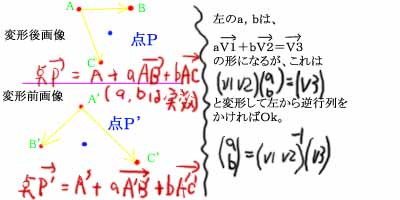
上図の変形後画像における実数a,bの値を、上図の右の方法で求めたのち、変形前画像に、そのa,bを代入して点P’の位置を確定させる。
この図の右下にある2次元のベクトルを2つならべて2行2列の行列にする方法は、よくやるのだが、悲しいかな数学的に、これの正式な表記方法が無い。(と思う) よって、ここにあるのは、やねうらおの勝手な表記法に基づくので、数学の試験で真似してバツされても、やねうらおに文句を言わないように(笑)
ということで、最後のところは、V1,V2が一次独立であれば逆行列を持つ。すなわち、A,B,Cが同一直線上になければ良い。CMorpherの実装では、同一直線上にある場合は、3番目に遠い点を破棄し、4番目の近傍点を持ってくることになっている。
また、本当は、近傍3点の対応ではなく、近傍4点の対応を見たほうが良いような気もする。んーと4点だとどうなるんでしょうか..?
上の図みたく、変形後画像の近傍4点A,B,C,D、それに対応する変形前画像4点A’,B’,C’,D’。
点P = A+aAB + b (AC+aCD) [イタリック体はベクトル,a,bは実数]
として、結局 a V1 + b V2 + ab V3 = V4 みたいな式が出てきて、これはばらさないと解けないから、V1の要素を(V1x,V1y)、V2以下同様として実際にばらすと、
1) aV1x + b V2x + ab V3x = V4x
2) aV1y + b V2y + ab V3y = V4y
という式が2本出てきて、V3xかV3yのどちらかが0ならば、abの項が無い式だということになるので、そいつ使ってもう一方の式に代入すればbは消せるから、結果、aの2次式になって、あとは解の公式で、A,B,C,Dがねじれていなければ解が1つ出てくるはず..。いや、モーフィングだからねじれてたりするからやらしいんだけど(笑)
あと、V3x,V3yの両方が非0なら、もう片方の式に代入して項abの存在しない式と、項abしか存在しない式が出来るから、前者を後者に代入すると、またもや2次方程式が出きて、あとは以下同様。んーこれで、合ってますか?
そんなわけで、近傍4点をとるのはやめましょう^^; (なんや?やめるんかい〜)
以上のような経緯でリアルタイムモーフィングルーチンが完成した。(ここの説明でわからん人はyaneSDK2ndのCMorper見てね^^;) リアルタイムにやっているのは、まだ、市販ゲームでもほとんど見受けられないので、ちょっぴり新鮮だろう。やねうらおのほうは、これを使ったゲームを作る予定はいまのところ無いので、これを読んでいるソフトハウスの方は、是非、一番乗り〜に挑戦していただきたいと思う。
第六章.未来形でプログラミングする 2000/10/13
C++では、関数を、すべてvirtualにするというのが、最近のプログラミングスタイルの主流になりつつある。そもそも仮想関数呼び出しのオーバーヘッドなんて最近のマシンならば確実に無視できるオーダーだし、どのクラスから継承するかなんてクラス設計段階ではわからないので、あとあとのためにもvirtualでなければならない。
そんなわけで、コンストラクタ以外には何も考えずにvirtualと書くのもいいかも知れない。少なくとも、やねうらおは最低限のマナーとしてデストラクタにはvirtualと書いている。(派生クラスのポインタを基底クラスのポインタへアップキャストしたあと、そのポインタをdeleteしたときに派生クラス側のデストラクタが呼び出されるようにするため)
さて、今回は、yaneSDK2ndの掲示板から引用させていただくことにする。yaneSDK2ndは、実際にプロもしくはプロに近い方が多数使われているだけあって、質問のレベルが高いし、バグ報告もやたら早い。(ありがたい限りです)
タイトル:yaneSDK非対応の画像の読みこみ方 発言者:MASATO 日付:2000/10/6 13:11:36 何か質問ばっかりしていてすみません^^; yaneSDKでは対応していない画像の読みこみ方について質問です。 とりあえず仮にPNGとしておきます。 (将来は妖しげな暗号化BMPとかも読みこみたいです) すでに、PNG読みこみ関数は作ってあるのですが、 問題はこれをどこに書くか、です。 1、SPIを作る。 あっさり終わりそうですが、あまり外部ファイルを作りたくありません。 特に妖しげな暗号化BMPという話になってくると、誰でも利用できるSPIにするのは あまり好ましくありません。 2、yaneGraphicLoader.cppをかりかりと書きかえる これを変更すれば、CDIB32やCDIBitmap、CPlaneのどれでも読みこみが可能になって とても良さそうですが、 yaneSDKを利用する他のアプリケーションにまで支障が出ます。 PNGの読みこみは、libpng.libとzlib.libが必要になるので、 PNGを使わないほかのアプリケーションにまでこれらのライブラリが必要になってしまいます。 それ以前にソース自体を書きかえる、というのはyaneSDK2のバージョンUpに対応するのも 大変ですし、出来れば避けたい所です。 3、CDIB32やCPlane等のクラスを派生させて、PNGから読み込むための関数を作る。 これも中々良い方法なのでしょうが、いくつものクラスに同じ処理を書かなければ ならないので、少し大変です。 というわけで、思いと一致する方法が見つかりません。 そこで要望なのですが、 CDIB32やCPlane等の内部でCGraphicsLoaderから画像をロードしているクラスに、 CGraphicLoaderを指定する機能をつけて頂けないでしょうか? これだと自分でCGraphicsLoaderを派生させればすぐ終わりです。 例えば、CPlane::Load関数の引数にCGraphicLoaderへのポインタを指定すると、 それから読みこんでくれるというのはどうでしょうか? =>でもCGraphicsLoaderのLoad,GetSize,Render等がvirtualでないと役に立たないかもしれません =>これらの関数のvirtual化希望です。^^; |
yaneSDK2ndを知らない人のために、このMASATOさんの書き込みを少し補足します。CPlane,CDIB32という、1枚の画像を保持するクラスがあって、そのなかでファイルから画像を読み込むためのLoadという関数があります。この関数のなかで、bmp,jpegなどの画像を読み込むために、HDCを渡せば描画してくれるCGraphicLoaderというクラスにそれを依頼します。
いま問題となっているのは、CGraphicLoaderを自分なりにカスタマイズしたCGraphicLoaderExというようなクラスを作ったとき、それをCPlane,CDIB32から適切に呼び出す(=生成し、解体する)ための手段です。yaneSDK2nd側のソースを書き換えればそれで済むのですが、そうなるとバージョンアップのたびに変更する手間が発生するので、普通はやりたくないはずです。
こういうのは、ライブラリ設計者と、利用者とが違うような場合、頻繁に発生します。その割には、典型的なデザインパターンとして分類されません。(されてないよね?)
MASATOさんが言われているように、CPlane::Loadの引数としてCGraphicLoaderのポインタを与えてやるのは一つの手でしょう。ただし、CPlane::Loadの仕様をいまさら変更したくないです。仕方ないので、CGraphicLoaderのポインタを設定するstaticな関数をCPlaneに追加すると?
| void CPlane::SetGL(CGraphicLoader *pGl) { m_Gl = pGl; } |
この関数で、事前にCGraphicLoaderExのインスタンスへのポインタを渡して、CPlane::Loadのなかでは、このm_Glを間接でCGraphicLoaderのメンバ関数にアクセスすれば良いように思うかも知れません。
しかし、これでは、
1.CGraphicLoaderExのインスタンスが利用者側に必要(利用者側にその解体責任がある)で、しかも、
2.CPlane::Loadのなかで、CGraphicLoaderのコンストラクタ/デストラクタが呼び出されません。デストラクタの呼び出しまでを期待して設計している場合は、これは不可なのです。
ということで、これは、ありがちな解決策のわりには、ダメなクラス設計なんです。
さて、どうしましょう?
1.は、解体責任を、このCPlaneが受け持てば良いわけで、それにはauto_ptrを使うと簡単でしょう。
| void CPlane::SetGL(auto_ptr<CGraphicLoader>
pGl) { m_Gl = pGl; // m_Glはauto_ptr<CGraphicLoader> } |
これならば、利用者側でCPlane::SetGL(new CGraphicLoaderEx);として、auto_ptrに所有権を持たせておけば、あとは勝手にm_Glが解放してくれることでしょう。つまり、解体責任からは逃れることが出来ます。これが非常に大切です。解体責任をユーザー側に押し付けるのは、よくありません。
2.は、スーパープログラマーへの道「第C7回 functorは函数合成の夢を見るか(何のこっちゃ^^;) 」でも書きましたが、関数の引数にクラス名を渡せないテンプレート展開の弱さに原因があるわけで、この場合ならば、FactoryMethodを使うと良いかも知れません。つまりは、こんなクラスを作って、
| // FactoryMethodを利用 class CGraphicLoaderFactory { virtual CGraphicLoader* CreateInstance( ) { new CGraphicLoader; } }; |
とやり、必要ならば、ユーザー側で、これの派生クラス、たとえば
| class CGraphicLoaderFactoryEx : public CGraphicLoaderFactory
{ virtual CGraphicLoader* CreateInstance( ) { new CGraphicLoaderEx; } }; |
を、CPlaneにセットしてやる。具体的には、
| void CPlane::SetGLFactory(auto_ptr<CGraphicLoaderFactory>
pGlf) { m_Glf = pGlf; // m_Glfはauto_ptr<CGraphicLoaderFactory> } |
で、CPlane::SetGLFactory(new CGraphicLoaderFactoryEx);とやってセットする。
その後、CPlane::Loadで、このCGraphicLoaderのインスタンスが欲しくなったら、
| auto_ptr<CGraphicLoader> pGl( CreateGraphicLoader( ) );} |
とやって、所有権付きのCGraphicLoaderを生成すれば良いのです。もちろん、
| // Prototypeパターンで解決 CGrapicLoader* CPlane::CreateGraphicLoader ( ) { if (m_Glf == NULL) return new CGraphicLoader; else return m_Glf->CreateInstance( ); } |
ですね。ここまで見て、functorとの類似性に気づかれたかも知れません。そうです。私に言わせれば、こんなことしなくてはならない原因は、テンプレート展開が甘さゆえであって、関数の引数にクラス名を渡せないから代理で、それを生成するオブジェクトを渡してお茶を濁しているに過ぎないのです。FactoryMethod and PrototypePattern w/z auto_ptr、なんて言うと流行りの歌みたいでカッコイイかも知れないですが(笑)、その実態はかなり惨めです。それぞれの用例のうちでもかなりみっともない部類に入ります。まあ、こうするしか他に方法は無いような気がしますが…。
そんなわけで、未来形でプログラミングするためには、かなりサブーイプログラミングが待ち構えています。そもそも、最後に派生されたクラスを使う構文さえあれば、こういう必要は無くなります。あるいは、クラス宣言時に、そのクラスと摩り替える特殊な派生方式があれば良いのです。たとえば、こんな感じの..
| modified class CGraphicLoader { // CGraphicLoader修正のための擬似派生クラス } |
後者は、私が長年欲しいと思いつづけているものです。このような機能なくして拡張性を考慮に入れていない他人のライブラリを自由に拡張することは出来ないでしょう..
第六章のフォローアップ 2000/10/14
テンプレートで、上のFactoryMethod + Prototypeパターンを用意してみた例。
/*
prototype_factory : FactoryMethod + PrototypePattern w/z auto_ptrEx
programmed by yaneurao(M.Isozaki) '00/10/14
*/
#ifndef __YTLPrototypeFactory_h__
#define __YTLPrototypeFactory_h__
#include "auto_ptrEx.h"
// Factoryテンプレート
class TFactoryBase {
virtual void* CreateInstance() { return NULL; }
}; // 基底クラスを用意するのは、
// 継承関係のあるFactoryクラス間でのアップキャストが不可になるため
// メンバ関数テンプレートが使えればそれに越したことがないのは言うまでもない。
template<class T> class Factory : public TFactoryBase {
public:
virtual void* CreateInstance() { return new T; }
};
// FactoryMethod + PrototypePatternテンプレート
template<class T> class PrototypeFactory {
public:
T* CreateInstance() { return reinterpret_cast<T*>(m_lpFactory->CreateInstance()); }
void SetFactory(TFactoryBase* lp) { m_lpFactory = lp; }
// コンストラクタでは、ディフォルトFactoryを生成する
PrototypeFactory(void) : m_lpFactory(new Factory<T>) {}
virtual ~PrototypeFactory() {} // place holder
protected:
auto_ptrEx<TFactoryBase> m_lpFactory;
};
#endif
|
見ての通り。
yaneSDK2ndのYTLに含まれているので、もしこれでわからない人は、そちらの解説も合わせて参照すると良いでしょう。
結局、ポインタが得られるわけですが、これに代理母パターン(「スーパープログラマーへの道 第C9回 ポインタを捨てて、街へ出よう!」)を適用すれば、ユーザーにしてみれば生成と使用に関して、何の意識もする必要がなくなります。
そもそも、->(アロー演算子)とか、スコープ解決の::だとか、馬鹿でないの?と言いたいです。同じことを表現するのに、複数の表記があることは忌むべき事態です。ちなみにC#では、すべて .(ドット)に統一されます。これは当然の帰結です。
次回は、C#の詳しい言語仕様と、その問題点について書きます。