
第B1回 マルチスレッディングの嫌らしさ(もう嫌やねん!) 00/06/14
「肌の色は肌色か?」
去年の11月ぐらいにクレヨンから肌色が無くなるというニュースが流れていました。ご覧になった人も多いでしょう。人種差別につながるからだそうです。まあ、人種差別につながるというのは、わからないでもないですが、ちょっと待てよ…
「水色は水の色か?」
水は無色透明ではないのか?
「空色は空の色か?」
夕焼けは空ではないのか?夜空は空ではないのか?
「緑色は緑の色か?」
「茶色は茶の色か?」
などと考えていると、眠れなくなる。(そうでもないか^^)
クレヨンで肌の色を塗るのに、肌色だけをベタ塗りする子供はあまりいない。子供でさえ、肌色だけでは肌の色を表現できないことを知っている。同様に、水を表現するのに、水色をベタ塗りしないし、空の色を描くのに空色をベタ塗りしない。(だろう) 肌色というのは、肌の色を表現するための、ひとつの可能性に過ぎないというのに…
さて、第AF回のSTLのlistについて、さ~さんが、詳細まで調べてくださったので、紹介しておきます。(あんがとね~>さ~さん)
http://www1.webnik.ne.jp/%7Esanami/codemaster/index.html#CODE18
ところで、いま開発中のyaneGameSDK2ndですが、マルチスレッド対応をやめたいと思います(笑)
一応、アプリケーションクラスは窓を一つ保持し、メッセージポンプとワーカースレッドの2つのスレッドから形成されていたのですが(ある程度うまく動作していたのですが)、二つほど以前から懸念していた問題が解消しないので、マルチスレッド非対応にしたいと思います。
ひとつ目は、スレッド間の排他処理です。排他処理自体はWin32のCriticalSectionで出来るのですが、何かの折にCriticalSectionを記述するのが面倒です。それを一元管理しようと思えば、サーバスレッドのようなものを用意して(そこでスレッド間の排他処理を行ない)、各ワークスレッドはそいつに対してメッセージ送信し、サーバスレッドがそのメッセージを改めて配信/処理する形には出来ますが、構造が複雑になるのと、速度が遅くなること、そしてゲームに使うだけなので、そこまでするほどの価値があるとは思えません。
デバッグウィンドゥを生成して、そちらにデバッグメッセージを出してデバッグ出来るというのは非常に便利だったのですが、さ~さんからは「そんなもんぐらいTCP/IPか何かで送ったほうが余程便利では?」と突っ込まれ、それもそうか~とか思いました^^
もう一つの問題というのは、アプリケーションクラスにつき一つ用意しなければならないものを記述するためのC++の構文が存在しないことです。あるクラスXYZのstaticなメンバにしてしまうと、それは他のスレッドからも参照できてしまいます。アプリケーションクラスにつき一つにしたければ、アプリケーションクラスのメンバとしてXYZを持たせるしか無いのですが、そうすると、クラスXYZは、モジュール性(modularity)を損ねてしまいます。
クラスは、それ自体で完結しなければならないのに、クラス自身の記述能力が弱いがために自己完結できないのです。C++がオブジェクト指向言語もどきだと言われる所以ですね。
第B2回 分岐予測のペナルティ(ペナルティ回避スーパーテクニック!?) 00/06/16
第AD回でご紹介したライフ府中中河原店(知らんっちゅーに)の半額おじさんの行動パターンを調べたのでご報告します。
例)お寿司 定価798円
閉店2時間前 100円引き
閉店1時間前 200円引き
閉店40分前 300円引き
閉店20分前 半額
だいたい、200円引~300円引が買い時で、そのときに売り切れてしまうことが多い。サラダなどは、もう少し早いタイミングで半額になる。
競争率が激しい商品は、半額おじさんがシールを貼っている跡をつけて、自分の買い物カゴに投入する有様である。
そんななか、やねうらおは、信じられない光景を目にした。サラダ半額のシールを貼っている半額おじさんの横に歩みより、そのおばさんは自分の買い物カゴのなかの寿司を指して、ここにもシールを貼りなさいとジェスチャーしたのだ。例によってデジカメで撮影した映像は肖像権侵害となりうるので、イメージ図でご理解願おう。
やねうらおの計算が正しいならば、お寿司が半額になるのは、少なく見積もってもあと25分と30秒は待たねばならない。よしんば半額になったとしてもその栄光を掴み取ることが出来るのはごく一握りの人たちであって、なおかつ運が悪ければ半額になる前に売り切れてしまい、勝者不在のまま闘いに終止符を打たねばならないだろう。(なんのこっちゃ) なのに、そのおばさんときたら、図々しくかつ厚顔無恥にもいますぐ半額にしなさいという暴挙に出たのだ。こんなことが許されていいのだろうか?
しばらく硬直する半額おじさん。固唾を飲んで見守る周囲のおばさんたち。少考の末、なんと半額おじさんは、おばさんの買い物かごのお寿司に素早く半額のシールを貼ったのだった。
一本勝ちです!!半額にしろおばさんの一本勝ちです!!強引に技を極めに行った半額にしろおばさんの一本勝ちです!!いま彼女の買い物カゴには、半額シールの貼られた輝かしい半額寿司が入居しております!!人類が自力で半額寿司を獲得した世紀の大偉業の瞬間です!!しかし、こんな裏ワザが許されていいのか。伊藤家の食卓に応募しなくちゃ!(葉書の無駄やっちゅーに^^)
はてさて、分岐予測のペナルティですが、素のPentiumではそれほど大きくないので、よほどでない限りは無視してプログラミングされていることと思いますが、MMX、そしてPentiumII に至ってはそうではないのです。高度なパイプライン化の影響でMMXのころよりPentiumII のほうが分岐予測のペナルティは大きいのです。だいたい、10~20clock(だったと思います) ノートパソコン等で普及しているCeleronは不幸にして(?)PentiumII に分類されるので、分岐予測のペナルティは馬鹿に出来ません。また、今後パイプラインのステージが増えると、さらに大きな分岐予測のペナルティが課せられる可能性もあります。これはRISC的なアーキテクチャの宿命と言わざるを得ません。
そこで、なるべく分岐しないプログラムを組むことが大切になります。分岐するものも、分岐させずに済ますことが大切です。ヌキ色付きの転送ルーチンを書くとします。普通、ヌキ色であるかどうかをチェックして、ヌキ色であれば転送しないというプログラムを書くでしょう。C言語風に書けば
if (Src != ColorKey) Dst = Src;
と。しかし、PentiumIIでは、こいつがまた遅いのです。私が最初に考えたのは、
Dst = Src・Mask + Dst・~Mask; // ・はand, + はor, ~はnotを表す
とやることです。Maskは言うまでもなくSrc==ColorKeyならば0xffffffff,Src!=ColorKeyならば0です。MMXには、これを一命令で行なうためのPCMP命令があります。あまり洗練されたコードではありませんが、こちらでやったほうが下手に分岐させるより速いというのだから、驚愕です。
余談ですが、マスクの生成は、Pentiumでも
XOR eax,ebx
ADD eax,0xffffffff
SBB eax,eax
とやって、ADDでZフラグをキャリーに変換して、SBBでキャリーからマスクに変換するという流れで行なうことが出来ます。
それはともかく、Maskと~Maskを作る部分が少しもったいない気がしたので、さ~さんと相談していたら、
(x^y)^x == y
(x^y)^y == x
というのを使えないか?ということになって(→XORについては第A9回を参考にせよ)、
Dst = Src ^ (( Src^ Dst)・Mask);
とすれば、Mask=0xffffffffならば右辺はSrc^Src^Dst == Dst,Maskが0ならば右辺はSrc ^ ( 0 ) == Srcとなるという結論に至りました。なかなか感動です。コンペアしたのちに、2つの値から選択するというのは頻繁に使うので、それらはすべてこのコーディングで済ませることが出来そうです。
とりあえず、何年後にどこかの掲示板で書いたときに、プログラミングど素人君に、誰それのをパクってるだとかお前は他の人がフリーとして公開しているものを自分が発見したかのように思い込み使っているだとかマナーに反しているだとか寝言言われると癪に障るので(笑)、ここに書いて証拠として残しておくことにしましょう^^
ちゅーか、こんなテクニックぐらいオリジナルを主張する気はまったくないんで、自由に使ってくださいな。
'00/06/17 補足
よく考えると、MMX命令を使うことにより2Pixelずつ変換できるというアドバンテージによってスピードアップしたのであって、分岐予測のペナルティで遅くなっていたわけではないような気がします。まあ、そこはビット演算テクニックの一種ということでご了承くださいな^^
ちなみにPentiumPro以降にはCMOV(Conditional Mov)というのがあって、フラグが立っていたら転送するというときにはこの命令が使えます。(この命令でやったほうが速い場合もあります) ちまたに普及しているCeleronはPentiumII に分類されるので、当然、PentiumPro以降であって、この命令が使えます。QWORDずつ行なうときは、ここで紹介した方法でMMXレジスタを使って行なうほうが速いですが、DWORDのときはCMOVのほうが速い場合も考えられます。Celeronの普及率を考えるとCMOVでの転送も検討に含めたほうが良いのかも知れません。
第B3回 飽和加算と飽和減算(違いのわからない男の非αブレンディング) 00/06/19
なんか最近、同業他社でプログラムされている方からやたらとメールをいただくんですが(笑)、何か私は悪いことでもしたというのでしょうか^^ もちろん、名前はここには出せませんが、相当有名な方が含まれています。
そんな同業他社さんのある方から、「過去ログを楽しく読ませていただいています」等のメールをいただき、第9F回でやっていた飽和加算の話が中途半端で終わっているとの指摘を受けたので、簡単に解説したいと思います。(私は同業他社だからと言って敵対視とかしていません。それは技術力が自分より下だと思っているからではなく、基礎技術は全体で共有すべきだと考えているからです)
さて、飽和加算と飽和減算は、MMX系ならばそれ専用の命令がありますが(というかMMXにはpacked飽和演算ぐらいしかアドバンテージがないという話もある)、素のPentiumではどうすれば良いのでしょうか?
たとえば、1:1のブレンドです。単純に考えれば、RGBが下位から8bitずつで構成されているDWORD(無符号32ビット。上位8bitは0だと仮定)で1つのピクセルが構成されているとして、このとき1:1のブレンドはどうすれば良いか?ということです。
単純に考えれば、
dst = (src + dst) >> 1;
でよさそうですが、繰り上がりによるゴミが出ることを考慮すれば、
dst = ((src&0xfefefefe) + (dst&0xfefefefe))
>> 1;
になります。このときRGBのそれぞれ下位1ビットの精度が落ちることがありますが、それはそれでも良いような気もします(笑) だって、RGB=(255,255,255)とRGB=(254,254,254)との違いを目で見てわかるはずもないですし…。そうは言うものの、RGB=(255,255,255)のピクセルとRGB=(254,254,254)のピクセルとが近接していれば違いはわかります。
そこで、新しい技法の登場です(笑) 論理回路でadder(加算器)を作ったことのある人なら、わかると思いますが、
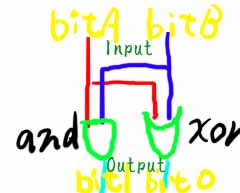
ですね。(また汚い図やな~(笑))
要するに、繰り上がりはand。その桁はxorになるわけです。これはnビットにそのまま拡張できて、
a + b = ( a & b )*2 + ( a ^
b );
になります。言うまでもなく( a & b)の部分が繰り上がりの処理、(
a ^ b )の部分が繰り上がらない部分の処理ですね。
ということは、これの両辺を2で割るときに、後者にだけ少しマスクをかけてやれば、packed byteによる加算平均が出来ます。(これ自体は、MMXの命令にも存在しないのでMMXを使っているときも有効)
つまり
(a + b)/2 = ( a & b ) + (((a ^ b)
& 0xfefefe) >> 1);
ですね。
これで1:1の高速ブレンドは出来ました。あとは、飽和加算と飽和減算です。これのオリジナルはSYNさんが考案されたものです。SYNさんのホームページは「天才プログラマ養成ギプス」の第3回でも紹介させていただきましたが、
でRGB5bitのときの式だけ書かれているので、僭越ながらここで解説させていただきたいと思います。^^
packed byteで加算したときの、各byteの桁溢れは、
(a + b) = ( a & b ) + ((a ^ b) & 0xfefefe);
を、0x01010100とandを取ることによって得られます。それをcとすると、そこからbyte単位のmask(桁が溢れたbyteだけ0xff。そうでなければ0)を生成するには
mask = c - (c >> 8);
とすればOKです。あとは、出力として
dst = (src + dst - c) | mask;
として桁溢れしていたところを0xffにすればOK。SYNさんは5bitのAddBlendとSubBlendの式をホームページに書かれているので、ここではRGB8bitのときの式を書いておきます。
AddBlend :
c = ((( src & dst )<<1)
+ ((src ^ dst) & 0xfefefe)) & 0x1010100;
mask = c - (c>>8);
dst = (src + dst - c) | mask;
SubBlendのほうも原理は同じです。式だけ以下に示しますので考えてみてください。
SubBlend : // ( dst = dst-srcの場合 )
c = ((( ~dst & src )<<1)
+ ((~dst ^ src) & 0xfefefe)) & 0x1010100;
mask = c - (c>>8);
dst = (dst - src + c) &
~mask;
しかし、この演算子の数を数えると10個もあるんですけど。つまり10命令必要ってわけですか?(笑) MMXで1命令で出来るものを10命令ですか?(笑) しかもMMXのときはレジスタは64ビット幅なので2ピクセルずつ処理できるというのに…。まあ、現実的な速度は出るので良しとしましょう。
('00/06/22 第B5回に追加記事あり)
第B4回 VirtualProtectってなんやったんや(東京って恐いところだよ~) 00/06/20
日曜は某女に呼び出されて、二子玉川園の「ワンダーエッグ3」へ行ってきました。某女は、歩くの速いです。「マイ(ここで一度区切る)ペースにあわせてくださいな」 マイ ペースって?「あのー、マイ扇風機とか、マイ本棚とか言うじゃないですか。マイ ペースですよ。だから」 ああ、やねさんの歩くペースに合わせろと? 「そうですそうです。牛になったつもりでお願いします」 私、牛ですかー?と突っ込まれながらも、無事ワンダーエッグに到着。
るんるん気分の某女を尻目に、ほとんど睡眠時間をとっていないやねうらおは、すっかり吐きそうになりました。私の子供のころに流行った言葉で言えば「死にかけ5秒前」 今風に言えば「てゆーかー、マジ死にそー」 いや、ホントに吐きそうだったんだかんな~(笑) ぜったい、いつか仕返ししてやる(笑) >某女
「僕ねー、しっかり寝ないと、単一電池が充電されないんですよー」 単一電池って何?という某女 「誰でも背中にあるじゃないですか。人間はみんな充電式の単一電池で動いてるんですよ」 あっそうと冷たい返事。 「しかし、熱いですねー。こう熱いと頭の水が乾いちゃいますね」 頭の水って何? 「誰でも頭の皿の上に水が充填されているじゃないですか。熱射病になって倒れる人は、みんなこの水が無くなったときなんです」 ふーん。 「水が無くなると、倒れるんです。だから、水がなくなる前に休むんです」 あっそう、と馬鹿を見るような目の某女。 「違うんですよ。本気にしてませんか。僕のことキチガイやと思ってませんか。待ってください!それは全てイマジネーションの話なんですよ。充電式の単一電池と頭の皿を心のなかに描いてますか。心のなかに描いていない人には、いくら言っても単一電池と頭のお皿は見えてきません」 そんなの見たくないけど、と言う某女。 「ちょっと待ってください。最後まで人の話を聞いてください。校長先生も言ってましたよね。人の話は最後まで聞きましょうって。言ってないか。まあその、人間って、何か嫌なことがあるとしますね。嫌なことがあると、胸のところにあるハート型のチョコレートが粉々になるんです。こっぱみじんこですよ。こっぱみじんこになった奴をまた、お箸で摘んでひとつひとつ皿の上に戻していくんですよ。子供のころ、お豆さんでやりましたよね?あれです。あんな感じです。絨毯の目に挟まってる奴とかなかなか取れないんですよー。でも、あんな感じでまた皿の上にひとつずつ戻すんです。戻すんですよ。イライラしたら負けです。完全に戻ったときには、ハートの形のチョコレートはまん丸に変形してたりするんです。それでもいいんですよ。わかりますか?」 ええ、なんとなく。 「それと同じです。僕は単一電池で動いているし、あなたも単一電池で動いてるんです。それが嘘とか本当とかは関係ありません。なぜなら、それは思考する上で仮想的に想定されたものだからです。では、もっと、イマジネーションを働かせてください。ここにソーダ水がある。もう、どこに?とは思いませんね。そうです。目の前にあるんです。そのソーダ水のなかには氷が入っている。それを<記号>として解釈してはいけません。なぜならば、氷は氷だからです。もし、そんな言語的束縛から逃れたいのならば、氷に手と足を生やしてください。生えてきましたか?それでは、氷に、頭もつけてみましょう。せっかくだから、彼のことは、氷さんと呼ぶことにしましょう。氷さんこんにちは!ほら、元気よく言ってみてください」 氷さんこんにちは。 「元気ないですね。まあいいでしょう。氷さんは、でもソーダ水のなかで溺れてるんです。なぜなら、自分の上に薄切りのレモンが乗っかっているからです。邪魔ですね。だから薄切りのレモンをストローでどかして、氷さんを助けてあげるのです。ストローを動かしてみましたか?」 ええ 「はい。やっと氷さんは生き返りました。ぷは~って言って、あなたに感謝しています。○○さんありがとう~って!でもそれはすべて嘘だったのです。なぜかというと、そんな氷さんはどこにも居ないし、もともとそんなソーダ水なんてどこにもなかったからです。しかし、あなたは果たしてそう思いますか?論理学の世界でp→qはpの否定 OR qですね。つまり前提が偽ならば、結果が真であろうと偽であろうと、全体としては真なのです。それの意味するところは、偽の前提から生まれてくるものは、真であろうと偽であろうと、不思議ではないということです。わかりますか?このコンテクストに即して言えば、あなたが有りもしないソーダ水の存在を認めた時点で、この世界は<定立>し、動き初めていたということです。だから、そこで氷さんが溺れていたことは、何ら嘘ではないのです。氷さんは確かに溺れていたし、あなたはそれを確かに助けたと」
その後も機関銃のようにしゃべり続けたような気がするのだが、自分は気がついたら公園で、椅子に横たわっていた。「大丈夫?」と僕のことを心配そうに覗き込む某女。ああ大丈夫だ。氷さんも無事だ。「氷さんて何?」と聞き返す某女のことを僕は何でもないと振り解いた。
はてさて。少し前の記事になりますが、第97回のVirtualProtectについて、apyon-ukyonさんから、こんなお便りをいただいたので、ご紹介します。
| こんにちは、とつぜんすみません。 今回、過去ログを楽しく拝見させていただいておりましたところ、 「第97回 ネイティブコンパイラ作成への短い道のり(短いんか?) '00/01/17」 の文章内で、機械語コードを関数ポインタでの呼び出しをおこなっている個所につ いてですが、 コール時に保護違反がおきるのは、配列x内が実行属性をもっていないとかそうい うことではなくて、トレースしてみればお分かりになると思いますが、単に、コン パイル時の最適化のために配列xの中身が確保されていないだけの話で、ちゃんと 関数ポインタを介してxを呼び出しています。しかし、呼び出した先はゴミデータ なので無理して機械語として実行した際に(メモリ)オペランドがおかしくヴァイ オレーションとなっているのです。デバッグ時には未使用だろうが全変数がスタッ クに確保されますが、リリース時には未使用もしくは、使用していてもコンパイラ の判断でその場での即値オペランドで代用できるものは確保されません。 今回の例では、VirtualProtect()を使わずとも、実際に配列xの中身を使用してい るプログラムをかいておけば呼び出しは可能です。 ただ、コンパイラはおりこうさんなので、直接要素を扱う(加減算とか、printf() への引数)とかでは即値オペランドに直してしまいます。ですから、 void test(BYTE *mat, int num) { int a; BYTE temp[10]; for(a = 0; a < num; a++) temp[a] = mat[a]; } のような、適当な直接要素を扱わないプログラムを混ぜておけば動作します。この へんはコンパイラの最適化しだいですが。 VirtualProtect()は今回の例では単に最適化させずに配列をちゃんと確保している だけです。 まあ、スタック上に確保しないで静的にとったならば初期化時にきちんと確保され るので未使用でも呼び出せますが。 もっとも、大きなプログラムとしてこのような、個別機械語ルーチンを扱うなら ば、実行時に個々にその場でヒープに翻訳しつつプールしていくわけですから、 データが確保されないなどということは起きないですのでガシガシとルーチンを コールできるはずです。 ボクも学校の実験でコンパイラを作成させられたのですが、EXEのフォーマットを まだ知らなかったので結局メモリ中にプールして実行させるという方法を取らされ ました。あのときは機械語中からコンパイラ内の描画関数などを呼び出すための thisポインタに泣かされました。 |
とのことで、早速Windows2000で確認したところ、確かにその通りでした。ということは、実行属性なんて関係なくて(笑)、自分のプロセスに属するメモリならばどこでも実行できるということのようです。ということは、VirtualProtectは、書き込み属性が不可になっているコード領域に、自己パッチを当てるため書き込み属性を与えるのに使える程度なんでしょうか…。(いまどき、誰もしないか)
第B5回 ビット演算ミラクルテクニック(とか一応言ってみる) 00/06/21
ビット演算(ビットand,or,xor,not)自体は、ビット単位での演算、すなわち以前も書いたpacked bitなわけです。
それに対して、足し算や引き算は、そのビットのキャリーが果てしなく駆け上がる(例0xffffffffに1を足すと、各ビットは繰り上がりつづけて0になる。将棋倒しみたいですね)非packed bit系の演算と考えることが出来るでしょう。
ビットマスクを生成するときのことを考えてみましょう。第B3回の
mask = c - (c>>8);
の部分ですね。cは飽和したpacked byteに相当する部分の一つ隣が1になっています。つまり、
c == 0x01010000ならば、mask == 0x00ffff00
というようにマスクが生成されれば良いわけですね。これを実現するために、右8回シフトしたやつを自分自身から引いています。
これは、100から1引くと、前述の将棋倒しによってFFになるのを利用しているわけです。しかし、(c >> 8)の状態からならば、将棋倒しで、その上位7ビットを操作することが出来ることに気づきませんか?
具体的には、
(c>>8) + 0x7f7f7f
です。これで将棋倒しは起こりました。結果は各byteに関して80 or 7fとなりますが、各byteのMSB(最上位ビット)は、最後にxorで反転してやればOKですね。つまり、
mask = ((c >> 8) + 0x7f7f7f) ^ 0x7f7f7f;
でOKなのです。これが、第B3回で示したコードより速いかどうかについてですが、代入が一回減るので、演算回数が1回増えますが、レジスタ効率があがるので、ループをアンロールしたときに差が出ます。おまけに、この演算は、
c = ((c >> 8) + 0x7f7f7f) ^ 0x7f7f7f;
c = ((c + 0x7f7f7f00) >> 8) ^ 0x7f7f7f;
c = ((c + 0x7f7f7f00) ^ 0x7f7f7f0000) >>
8;
と交換可能なので、
shr eax, 8
add ebx, 0x7f7f7f00
shr ebx, 8
add eax, 0x7f7f7f
とやって、ペアリングできます。(shr同士はペアリングできない)
さらに、最後の部分でxorが入っているので、飽和減算のときに必要になる反転マスク(~mask)を
mask = ((c >> 8) + 0x7f7f7f) ^ 0x808080;
とやって一発で生成できます。あと、最終マスクの生成ですが、
dst = (src + dst - c) | c;
で済みます。なぜなら、飽和したBYTEは、0xffでorするため、律儀に0x100引く必要はなく、最大はFF+FF=1FEなので、マスクに使った0xFFでもかろうじて桁の繰り下げが生じます。これにより、中間レジスタを1つ省略できます。
てなわけで、以上、3点セットでさ~さんに教えてもらったです。(なんや教えてもらったんかい!) こんなだから、子供のころによく靴を隠されたらしい19才の誇大妄想少年にまで馬鹿にされるのか~^^(なんのことかわからん人、すんません~。軽く読み流していただけると幸いです)
一応、以上3点セットは、さ~さんのオリジナルということで。もちろん、自由に使っていいそうです(笑)
第B6回 乗算高速化手法(とか言ってみる^^) 00/06/23
職場は暑いです。脳みそが煮えくり返ってます。(はらわたでないだけいいじゃんという話もある) 脳みそでお茶が沸きます。やねうらおは、暑さに弱いです。寒さにも弱いんですけど。(ダメ) つまりはデリケートに出来ています。みなさん、優しく取り扱ってくださいな。(なんのこっちゃ^^)
そういや、私が高校生のころの話ですが…。
「なあなあ、お湯を沸かすって表現おかしくないか?」誰かが僕に言った。やたらと日本語にこだわる連中だった。(こいつらの中には、プロの売文業者になった奴が3人もいる) 「ああ。落語にもあるな。嫁をもらうとか。誰の嫁をもらうんだい?みたいなの」
言語学に興味のあった僕は言った。「文法用語で言えば、prolepsisすなわち、予期的叙述法やよね。drain the land dryとか」 prolepsisなんて大きな辞書にしか載っていないような文法用語をさらっと言えてしまう俺は、なんてカッコイイんだろうとか自分の言葉に酔いしれていたときにK君は言った。
「僕はそうは思わない」(彼は、この後、大阪外語大学に入学し、現在、某大学で英語講師をやっている)
「僕はそれは未来形だと思う」と彼はつけ加えた。
僕は自分の耳を疑った。「未来形?何が未来形なんだよ?」
「嫁が!」K君は間髪入れずに答えた。
「嫁?それは名詞じゃん?」 「だから嫁は女の未来形なんだよ」 それを聞いた、そこにいた全員がなんとなく頷いた。
「ちょっと待て。ひょっとして、お湯は水の未来形なのか?」 「そうだよ」
「なら、女の過去形は女児なのか?」 「違うよ」
「えっ?なんで?未来形は嫁なんでしょ?過去形とかないの?」 「あるよ」
「なんなんや?女の過去形はなんなんや?」 「それは言われへん」
「なんで言われへんねん。おかしいやないか。女の過去形はなんなんや」 「それは大きなったらわかる」
「大きなったらって、俺とお前はタメ(同い年)じゃい!」 「だから語ってはならんのだ…」
「なんや?語ってはならんって?女の過去形なんで語ったらいかんのや?」 「女は過去形で語るな。女は“いま”が大切なんや」
「ちょ、ちょっと待て!それはお前の人生哲学やろが!」
この後、K君との喧嘩は、2時間ほど延々と繰り広げられることになるのだが、いま思い返してみて、K君。あんときゃ怒ってすまんかった。いまなら、なんとなくその気持ちが分かるような気がするぞ(笑)
そういや、いまゲームのライブラリを作り直してます。というか、これが終わらないとゲーム開発に着手できないんですけど(笑)、ゲーム開発に着手してから1ヶ月ぐらいしか開発期間が無い計算。ノベルとかならともかく、アクションゲーム。例によって、使い回しはほとんど期待できません。ホームページで馬鹿なこと書いてる場合ではないんでないか~。
いま、32bppのDIBに対するαブレンディングのルーチンを書いているのですが、何と言ってもPentiumは掛け算が遅い。32bit同士の掛け算で9クロック。しかもペアリングが出来ないので、ペアリング出来る1クロックの命令ならば18命令に相当するわけです。これが凄く痛いと思いました。(32bppという表現がわからない人もいるでしょうが、下位バイトからB,G,Rが入っていて、最上位バイトは0だと考えてください)
そこで、掛け算の回数を減らすことを考えたわけです。たとえば、一回の掛け算で2つのバイトに対する掛け算が出来ないかと。
つまりは、[0RGB]を右8回ローテイトして[B00G]というようになっていれば、これに8ビットのα値[a00a]を掛け算すれば、64ビットの演算結果のうち、下位16ビットがG×aで、上位16ビットがB×aであることが保証されます。
もう一捻りして、[0RGB]からそのままGだけマスクして[0R0B]にして、これにα値[0a0a]を掛けても良さそうですが、筆算してみればわかるように、下位のゴミが1ビットR×aに乗り上げてくることがあるので、不可なのです。
やりなおし。[0R0B]からこれにα値[a00a]を掛けてはどうでしょうか?これならば下位16ビットがB×a,上位8ビット0で、その下がR×aであることが保証されます。(わからない人は筆算してみてください。bit16~bit39が取り得る最大値はFF×FF=FE01だからFE01+(FE01<<8)=FEFF01で、bit40への繰り上がりがないことは保証されます。一応、図示。16進数の筆算を見たことが無い人もおられると思いますが、何進数であろうと考え方は変わりません)
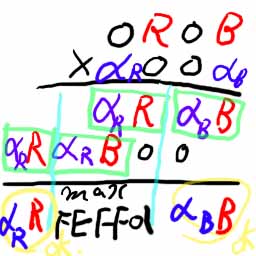
この[a00a]は事前に作成出来るので、OKでしょう。1回のMULで2回ずつ掛け算が出来ます。ループはアンロールして、2ピクセルずつ処理するので、このような考え方で、2ピクセルに対して3回のMULで計6回の掛け算が出来ます。(同様に[G0g0]に[a00a]もOKです)
ところが、これが最速かというと、そうでもないのではないかと思うのです。
たとえばテーブルを用いることです。精度を落としてテーブルを用いるのが一般的だと思われますが、フェードするときに非常に汚くなるので、ここでは精度を落とさずにテーブルを用いることを考えてみましょう。とは言っても256×256のテーブルだと64Kで、これはPentiumではL1キャッシュには入らないので、非常に遅くなります。α値が固定であれば、実際に参照されるのはリニアな256BYTEだけなのでOKという気もします。
ここで、ある事情により、α値が動的に変化する場合のことを考えてみましょう。そういうエフェクトが欲しくなることもあるはずです。
当然、256×256WORDのテーブルを用意すると全域に渡って参照されることになるのでL1キャッシュに入らずNGです。そこで、256×16WORDのテーブル、すなわち4ビットテーブルを用いて演算を分割することを考えてみましょう。つまり、
WORD table[256][16]; // 掛け算テーブル8Kがあるとして
BYTE x,y;に対して
x × y == x × (y & 15) + ((x × ( y >> 4))<<4) == table[x][y&15] + (table[x][y>>4] << 4)
と。うーん。これあんまり速そうでないんですけど(笑) 演算子の数からすると9命令ぐらいかかるような(笑) しかもL1キャッシュぎりぎりなんですけど。ということは、MULで9クロック使って2つの掛け算するのと、あまり変わらないのか…?
いい方法をご存知の方、おられましたらメールくださいな。
第B7回 委譲最適化(ってメジャーではないのか?) 00/06/25
やねうらおは、ホームページを開設して以来、プログラム関係の知り合いはやたら出来たんですけど、お絵かきさんには知り合いはほとんどいません。まあ、仕事柄、名のある人は周りに居ますが…。そういやうちの原画マンが言っていたんですが、なんでもお絵かきさんのコミュニティのなかでは、何万ヒット記念とかにCGプレゼントするのが常識だそうです。毎日、自分の友達のサイトのカウンターをチェックして、何万ヒットとか切り番が近づいてきたら、それ用のCGを描くそうです。そして、何万ヒット達成した瞬間にCGを贈るそうです。逆に、自分のサイトが何万ヒットか達したときに、友達から記念CGをいっぱいもらうそうです。年賀状とかは、みんなCGで送ってくるから正月は必ずメールボックスが溢れてしまうそうです。だから、正月は数時間おきにメールチェックをするそうです。
いやー、そういうのって、なんだか羨ましいような気もしますね(笑) 私のホームページの場合、「130万ヒット達成したみたいだから、4連結のアルゴリズムによる回転ルーチンあげるよ」とか「130万ヒット達成したみたいだから、新しく開発した、高速適応型RangeCoder(注:算術圧縮に変わる圧縮アルゴリズム)の論文をあげるよ」とか(笑)そういうのぐらいしか考えられません。(←これは特定個人二人への催促ではないつもりです。念のため^^) というか、何万ヒット記念で何かもらったことって一度も無いですし、記念祝いなら論文とかより、もっと心の和むものをくれ~とか思いますよね(笑) (いや、もらえるだけでも感謝しなきゃいけないか^^)
今回は、短く委譲最適化の話をします。PlainPentium用とMMX用、PentiumII用でそれぞれ専用のコードを書くことを考えます。C++の常識的なコーディングでは、抽象基底クラスCDrawBaseを用意して、そいつから各CPU用のクラスを派生させて、そいつに対して実装していきます。
PentiumIIはMMX用のコードと同じでいいやって関数がある場合は、PentiumII用のクラスCDrawPentium2はMMX用のクラスCDrawMMXを継承して、必要に応じてオーバーライドするかも知れません。
使うときは、CPUIDに応じて、
CDrawBase* lpDraw = CDrawPentium2;
などとしてダウンキャスト('00/07/03 これは誤り。C++の用語ではアップキャストと呼ぶのだ)して使いますね。もちろん、CPUIDに応じてnewするという部分だけ切り離して関数化することは出来ます。(デザインパターンで言われるところのFactoryMethodですね)
ところが、この部分がめっちゃうっとおしいと思うんです。そこで、
class CDraw {
public:
CDraw(void) {
switch (CCpuID::GetID()){
case 0 : m_lpDraw = CDrawPentium;
break;
case 1 : m_lpDraw = CDrawPentiumMMX;
break;
case 2 : m_lpDraw = CDrawPentium2;
break;
}
}
~CDraw() { delete m_lpDraw; }
CDrawBase* m_lpDraw;
};
あとは、CDrawにCDrawBaseと同じインターフェースを持たせて、CDrawのメンバ関数ではm_lpDrawに委譲すれば良いのですが(デザインパターンで言うところのPrototypeですね)、ちょっと待ってください。本当に委譲するだけの、こんな代理母のようなクラスを用意しなくてはならんのですか?その時の委譲コストはどうなりますか?
たとえば、
int XXX (int a, int b, int c, int d) { return m_lpDraw->XXX(a,b,c,d); }
このような委譲を行なう関数では、引数がローカルスタックに乗っているはずなので、暗黙で渡されるthisポインタの値だけm_lpDrawと摩り替えて、そのままjmpすれば引数のコピーは無しで済むはずです。(これをここでは委譲最適化と呼びます)
不幸にして、VisualC++6.0ではこの委譲最適化は行ないません。しかし、関数をインライン展開することによって、この委譲コストを回避することは出来ます。これに気づくのに約3時間。(かかりすぎ^^) 最初、ポリモーフィズムなんか使わずに関数内でswitch~caseで分岐したほうが速いんではないかと思ったぐらいです。
ところで、ディスプレイモードが変更になったとき、サーフェースはロストします。各bppごとのルーチンをこのようにポリモーフィズムを使って記述していると、そのロストに応答して、newし直す作業が必要になります。また、DirectDrawで発生したサーフェースのロストをどう捉えるかですが、クラス間の相互依存関係を排除するためには、独自のメッセージ千打ー(なんちゅー変換するんや(笑)→正:sender)と、そのディスパッチャー(メッセージを配信するやつ)を作ってやらなければならないような気がします。そんな価値が本当にあるのか(笑)
そんなことを考えながら、噂になっていたStroustrup氏への架空のインタビューを読み返しました。このインタビューはでっちあげで、やや技術的には拙い気もしますが、オブジェクト指向言語としてC++はどうなのかってのは、常に考えさせられるテーマではあります。ガーベジコレクタやスマートイテレータ(世間ではアクティブイテレータと呼ぶのか?)が無くても、別にプログラムが出来ないわけではないですし、回避できない問題でもないと思うのです。私の場合、主にC++でプログラムしてますが、なんてC++言語って馬鹿なんだろう!って思いながらも、それが故に満足いくプロダクツが出来ないというわけではないのです。thisポインタの他にownerポインタが欲しくなったり、クラス内クラスがなんでストレージ分かれてるの?馬っ鹿じゃないの~?とか思いつつも、どうにかこうにかやりくりしている自分がそこに居る。
10年前、僕が詩人として尊敬していたToolsの森社長が僕にこう言った。「やね君。OSにバグがあってもそこでアプリはきちんと動いているやないの?部分的な論理の欠陥が理論自体の有効性を無に帰してしまうかね?やね君。僕たちは、バグだらけの社会のなかで、アホさんたちに囲まれアホさんとして生きるしか無い。しかしそれは、そこから産まれてくるものがバグだらけであることは意味しない」と。余談ではあるが、この数年後、森社長はNiftyの翻訳フォーラムで「門外漢」というハンドルで『電子文体論』を掲載され、それは数多くの言語学関係者・文学青年の間に論議醸し出すことになる。
第B8回 CreateDIBSectionの謎(というほどのもんでもない^^) 00/06/26
そういや、ダウンキャストなんですが、私、ダウンキャストって、基底クラス方向への変換だと思ってたんですが、どうも違うようです。C++の用語では、クラス継承の階層図を書いたときに、基底クラスを上に、派生クラスを下に書くのが一般的なので、基底クラスにキャストすることはアップキャスト、派生クラスにキャストすることをダウンキャストと呼ぶようです。(OgaOgaさんより指摘あり) いままで、ずーっと間違ってたよ~(笑) 恥ずかしいなぁ。
さてさて。メモリ内に持った32bppのDIBは、下位からBGRなんです。これは、DirectDrawSurfaceが、そういう構造になっているビデオカードが多いからそれに準拠させたのです。言うまでもなくGDI系のCOLORREFは逆順ですよね。なぜにそうなっているかはやねうらおの知るところではないのですが、非常にうっとおしいです。
まあ、それはなんとか目をつぶるとして、次にメモリ内にQWORDでアラインして確保しておいたDIBのHDCを得たいんですよ。これが何と出来ないんですよ(笑) いやー、てっきりCreateDIBSectionで出来るのかと思っていたのですが、出来ないんですよ。愕然としましたねー。それにCreateDIBSectionでどうしてピクセルイメージは天地逆なんですか?そりゃ高さに負の値を指定すれば天地逆ではなくなりますけど(裏技?^^)
仕方ないんで、自前でピクセルイメージを確保するんではなく、CreateDIBSectionで確保したメモリを使うことにしようと思ったんですよ。これって、きちんとQWORDでアラインされてるんですか?DWORDではアラインされてそうですが、QWORDでアラインされているのか…。だって、MMX命令で転送しようとしたとき、QWORDでアラインされていないと二度書きになって10%程度、遅くなってしまいます。そこんとこ、どーなんや?と思って、実験しました。実験環境はWindows2000なのですが、返し値を調べたところ、なんと常に下位16ビットが0です。そうです、
なんと、64Kでアラインされています!
ちょ、ちょっと~。これは明らかにやりすぎです。やりすぎですよ、CreateDIBSection!!つまり16×16のDIBを作っても64Kも食うということですか?お前、ちょっと馬鹿にされたからって金属バットで殴ってしまうような奴やな?などとわけのわからない突っ込みをAPIに入れるのはやめましょう(笑)
私はこまぎれのbitmapを数多く使うので、こんなことは許せません。少し遅くなりますがHDCが欲しいときは一時的CreateDIBSectionで作り、そこからコピーしてすぐ解放するように変更です。もう、いい加減にして欲しいです。例の母親を金属バットで殴った17歳の少年(なんか実名、某掲示板に書いてあった^^)は「テレビに出て有名になりたかった」と供述しているそうですが、さしずめ、CreateDIBSectionは64K確保してやねうらおの日記に載りたかったというところでしょうか。(そんなわけはない^^) ※ '00/06/28修正 供述というのは私の勘違い。まだ捕まっていない(笑)
ところで、この返し値はHBITMAPですね。これからHDCを得るにはどうすればいいんですか?
HDC hDC = ::CreateCompatibleDC(NULL);
::SelectObject(hDC,hBitmap);
これでいけますか?CreateCompatibleDCでNULLを指定しているということは、現在のディスプレイモードに依存するような気がします。でも、ビットマップ側はDIBなんです。うーん?どうなるんや?というところですが、これでOKです。このhDCは現在のディスプレイモードには依存しません。うーん。謎多すぎ。それが出来るなら、指定のピクセルフォーマットでDIBを作れてもいいんでないのよー?などとWindowsに絡みたくなります(笑)
例のMicrosoftの裁判の結果、Windowsの隠しAPIは公開されることになったようですが、ひょっとしてこういうのって隠しであるんちゃうか?とか思いますね^^